Basic Paper Information
Paper Name: Translating Videos to Natural Language Using Deep Recurrent Neural Networks
Paper Link: https://www.cs.utexas.edu/users/ml/papers/venugopalan.naacl15.pdf
Paper Source Code:
About Note Author:
- Zhu Zhengyuan, graduate student at Beijing University of Posts and Telecommunications, research direction is multimodal and cognitive computing.
Paper Recommendation Reason
Suppose we have achieved Artificial General Intelligence (AGI) in the future. When we look back at the past, which era would be voted as the most important “Aha Moment”?
As an ordinary person without the ability to predict the future, to answer this question, the first thing we need to clarify is: where exactly are we now on the path to achieving AGI?
A common analogy is, if we compare the journey from starting attempts to finally achieving AGI to a one-kilometer road. Most people might think we’ve already walked between 200 to 500 meters. But the reality might be that we’ve only walked less than 5 centimeters.
Because among the various attempts on the path to the correct road, a large portion will make directional errors. When we go further and further on the wrong path, we definitely cannot reach the destination. Overthrowing existing results and starting over becomes inevitable. We need to be constantly cautious to avoid “forks in the road”.
Now there’s reason to believe (actually because we have to put our heads in the sand), we are on a correct path. If I had to say what about current technology doesn’t quite match my intuition, I would definitely rush to answer: We are not living in books or images.
Five hundred million years ago, when we were still flatworms, we already made continuous decisions in unknown environments to survive.
Two hundred million years ago, we evolved into rodents and possessed a complete operating system. What remained unchanged was the continuously changing survival environment.
Four million years ago, after primitive humans evolved the cerebral cortex, they finally possessed the ability to reason and think. But all this was before they invented writing and language.
Nowadays, when the human giant is trying to create superintelligence that exceeds its own intelligence, it mysteriously overlooks that superintelligence should also live in a continuously changing, dangerous world.
Back to the initial question, I would definitely cast my vote for models that use neural models to process video streams.
Translating Videos to Natural Language Using Deep Recurrent Neural Networks
Introduction to Video Captioning Task:
Generate single-sentence descriptions based on videos. One example is worth a thousand words:

A monkey pulls a dog’s tail and is chased by the dog.
History of Video Captioning:
Pipeline Approach
-
Identify
subject,action,object,scenefrom video -
Calculate confidence of identified entities
-
Generate sentences based on entities with highest confidence and preset templates
Before neural models became popular, traditional methods mainly used Hidden Markov Models for entity recognition and Conditional Random Fields for sentence generation
First Attempt with Neural Models:
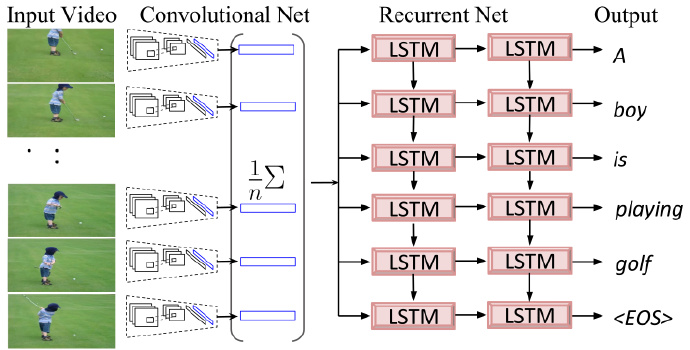
- Extract one frame from every ten frames in the video for analysis
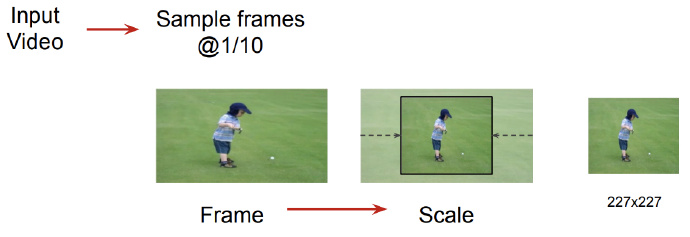
The human eye’s frame rate is 24 frames per second. From a bionic perspective, the model doesn’t need to process all frames in the video either. Then resize video frames for computer processing.
- Use CNN to extract features and perform mean pooling
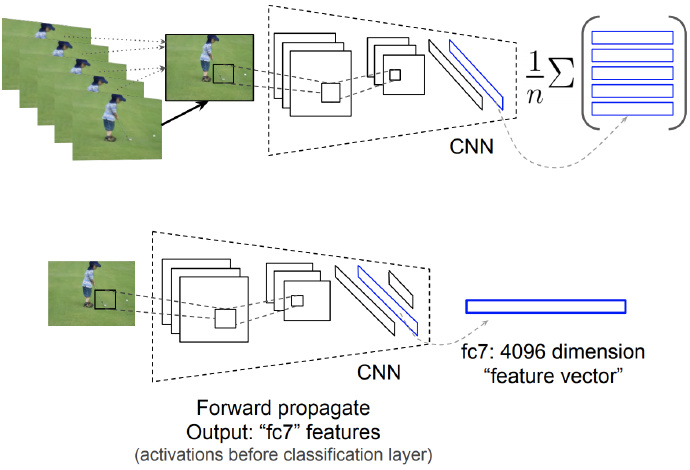
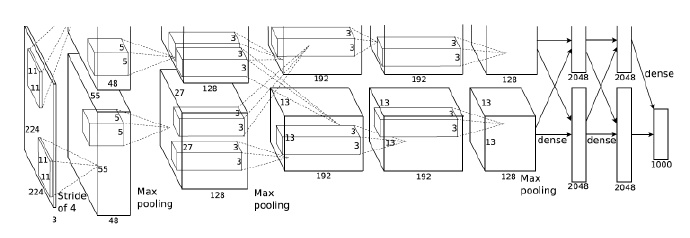
Pre-trained Alexnet [2012]: Pre-trained on 1.2 million images [ImageNet LSVRC-2012], extract features from the last layer (seventh fully connected layer) (4096 dimensions). Note: The extracted vector is not the final 1000-dimensional feature vector for classification.
Pool all video frames
- Sentence generation
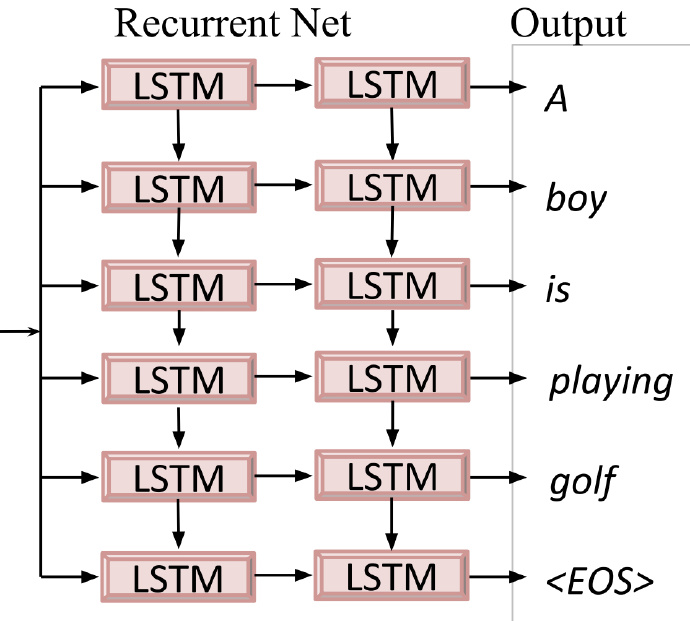
Transfer Learning and Fine-tuning Model
- Pre-training on image captioning task
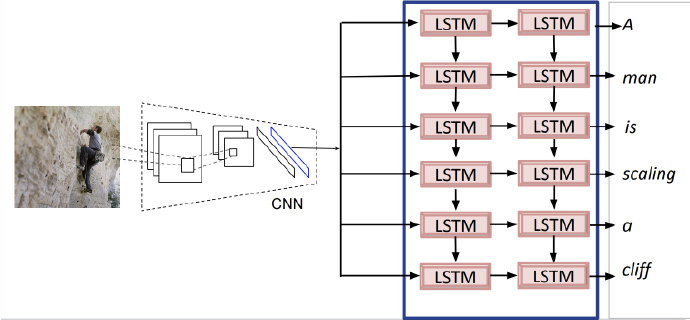
-
Fine-tuning Note that during video captioning:
-
Change input from images to video;
-
Add the mean pooling feature technique;
-
Use lower learning rate when training the model
Experiment Details
Dataset
1970 YouTube video clips: each about 10 to 30 seconds, containing only one activity, with no dialogue. 1200 for training, 100 for validation, 670 for testing.

Evaluation Metrics
-
SVO (Subject, Verb, Object accuracy)
-
BLEU
-
METEOR
-
Human evaluation
Experimental Results
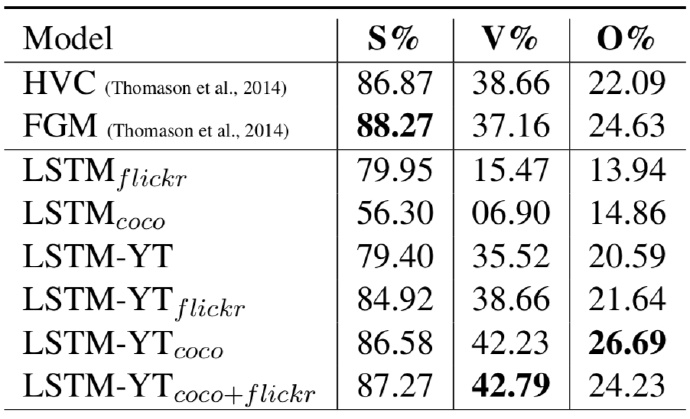
- SVO accuracy:
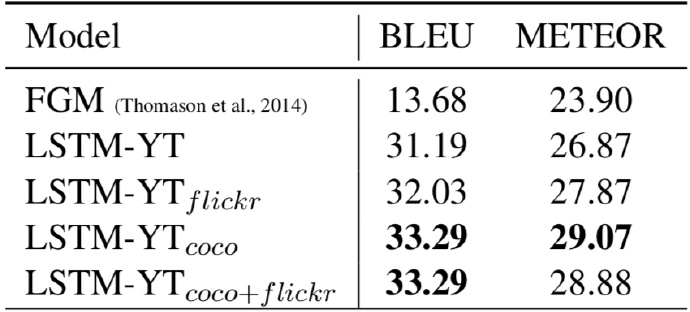
- BLEU and METEOR scores
Looking Back at 2015 Paper from 2019
Examining this paper with the hindsight of 2019, although the paper didn’t have Attention or reinforcement learning, it pioneered using neural models to complete video captioning tasks.
Reviewing previously raised questions, how to achieve:
-
Common sense reasoning.
-
Spatial position.
-
Responding to questions at different granularities.
The answer is very likely in us. The prefrontal cortex in the cerebral cortex controls personality (that voice appearing in your brain, that’s it). Although the cerebral cortex is only a thin layer of two millimeters on the outermost part of the brain (Yes, I’m sure it’s two millimeters), the role it plays is unprecedented.
Taking inspiration from the cerebral cortex, at minimum we need to let the artificial cerebral cortex also “live” in an environment similar to the real world. Therefore video is a good starting point, but only a starting point.

