Basic Paper Information
Paper Name: Describing Videos by Exploiting Temporal Structure
Paper Link: https://arxiv.org/pdf/1502.08029
Paper Source Code:
About Note Author:
- Zhu Zhengyuan, graduate student at Beijing University of Posts and Telecommunications, research direction is multimodal and cognitive computing.
Paper Recommendation Reason
This paper is a research result published at ICCV2015 by the University of Montreal. Its main innovation lies in proposing temporal structure and using attention mechanisms to achieve SOTA in 2015. By combining 3D-CNN to capture local information in videos with attention mechanisms to capture global information, it can comprehensively improve model performance. Another important contribution is the MVAD movie clip description dataset. This dataset has become a mainstream dataset in the current video captioning field.
Describing Videos by Exploiting Temporal Structure
Introduction to Video Captioning Task:
Generate single-sentence descriptions based on videos. One example is worth a thousand words:

A monkey pulls a dog’s tail and is chased by the dog.
Earlier models in 2015:
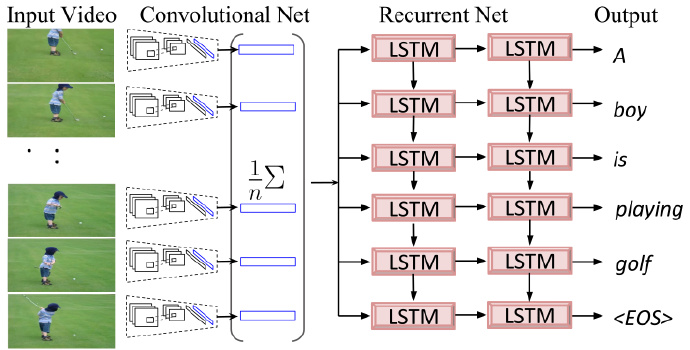
Problems with Pre-2015 Models
-
Generated descriptions don’t consider dynamic temporal structure.
-
Previous models use one feature vector to represent all frames in the video, making it impossible to recognize the sequential order of object appearances in the video.
Paper Ideas and Innovations
- Generate video descriptions through local and global temporal structure:
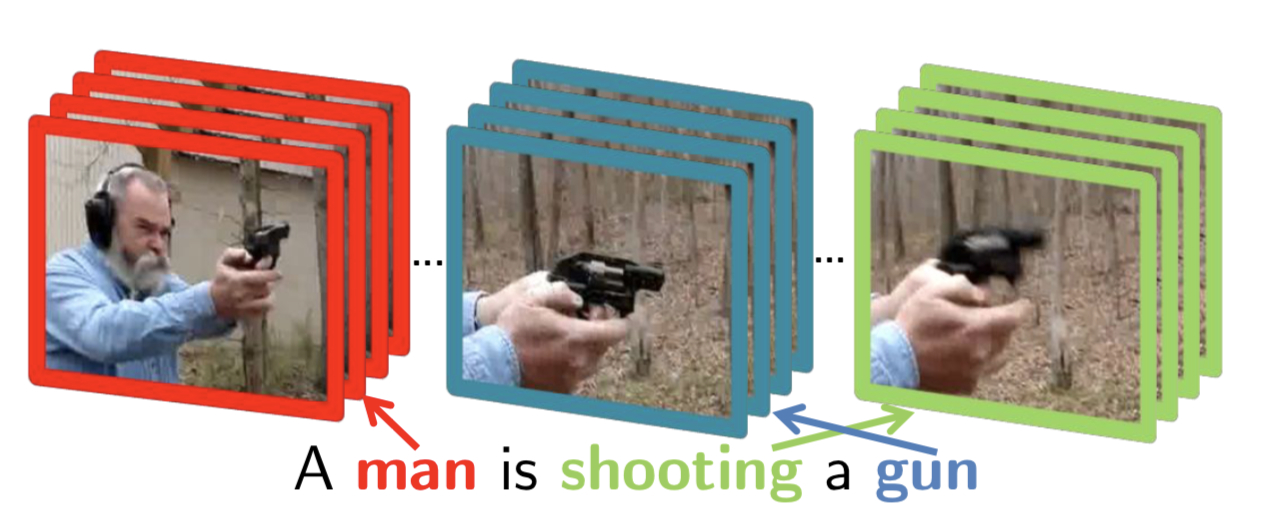
For each word generated by the Decoder, the model attends to specific frames in the video.
- Use 3-D CNN to capture dynamic temporal features in videos.
Model Architecture Design
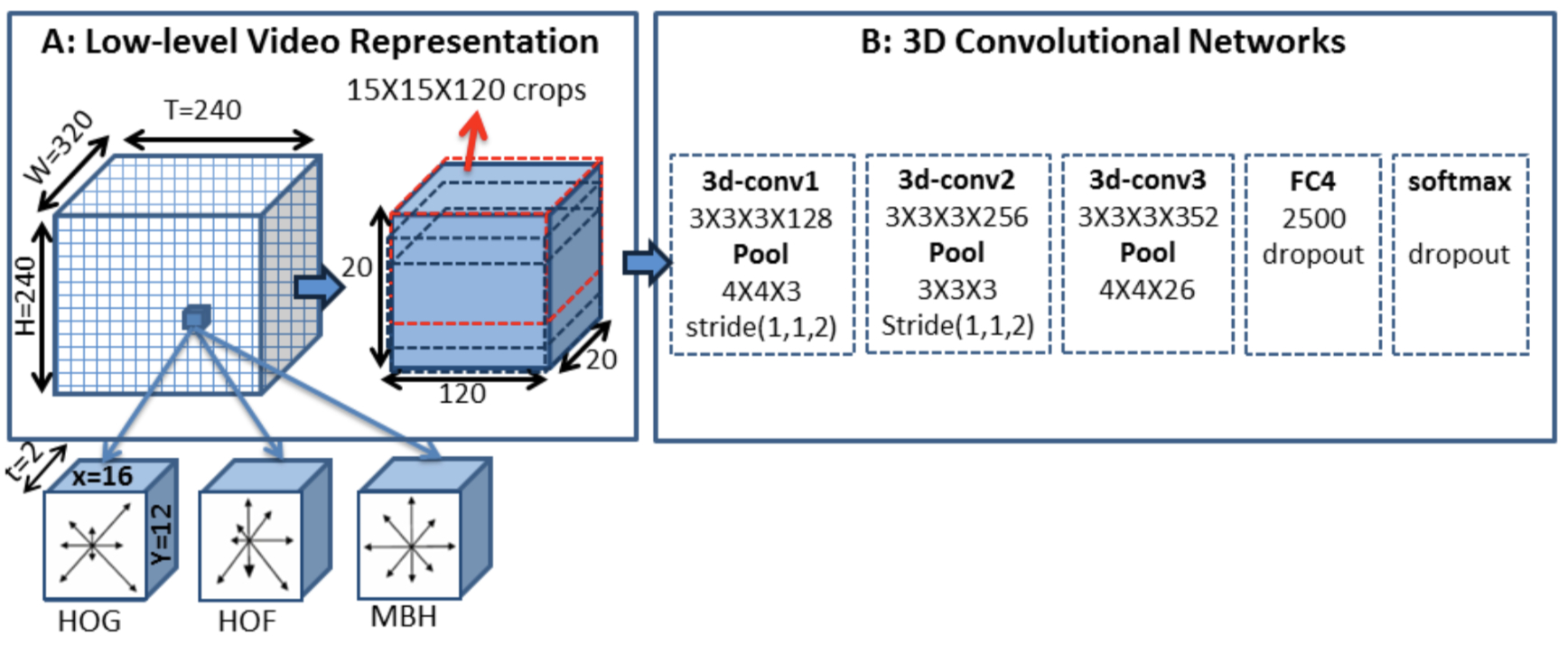
- Encoder (3-D CNN + 2-D GoogLeNet) settings: 3 * 3 * 3 three-dimensional convolution kernel, and 3-D CNN is pre-trained on action recognition dataset.
Each convolutional layer is followed by ReLU activation function and Local max-pooling, dropout parameter set to 0.5.
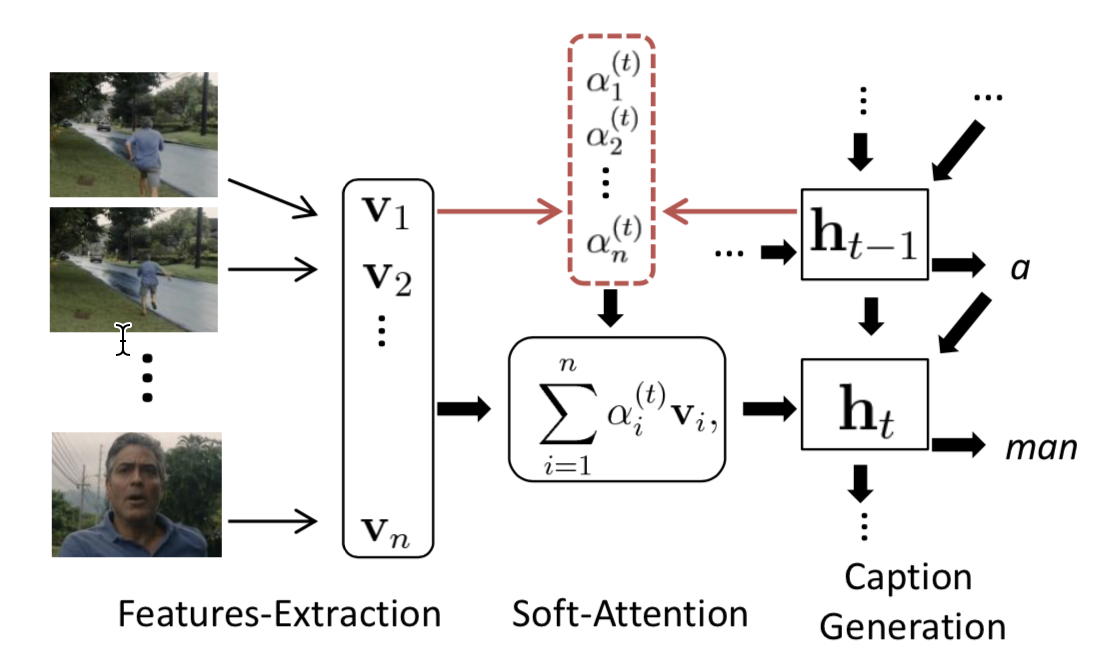
- Decoder (LSTM) settings: Uses additive attention as the attention mechanism. The figure below shows hyperparameter settings on two datasets:
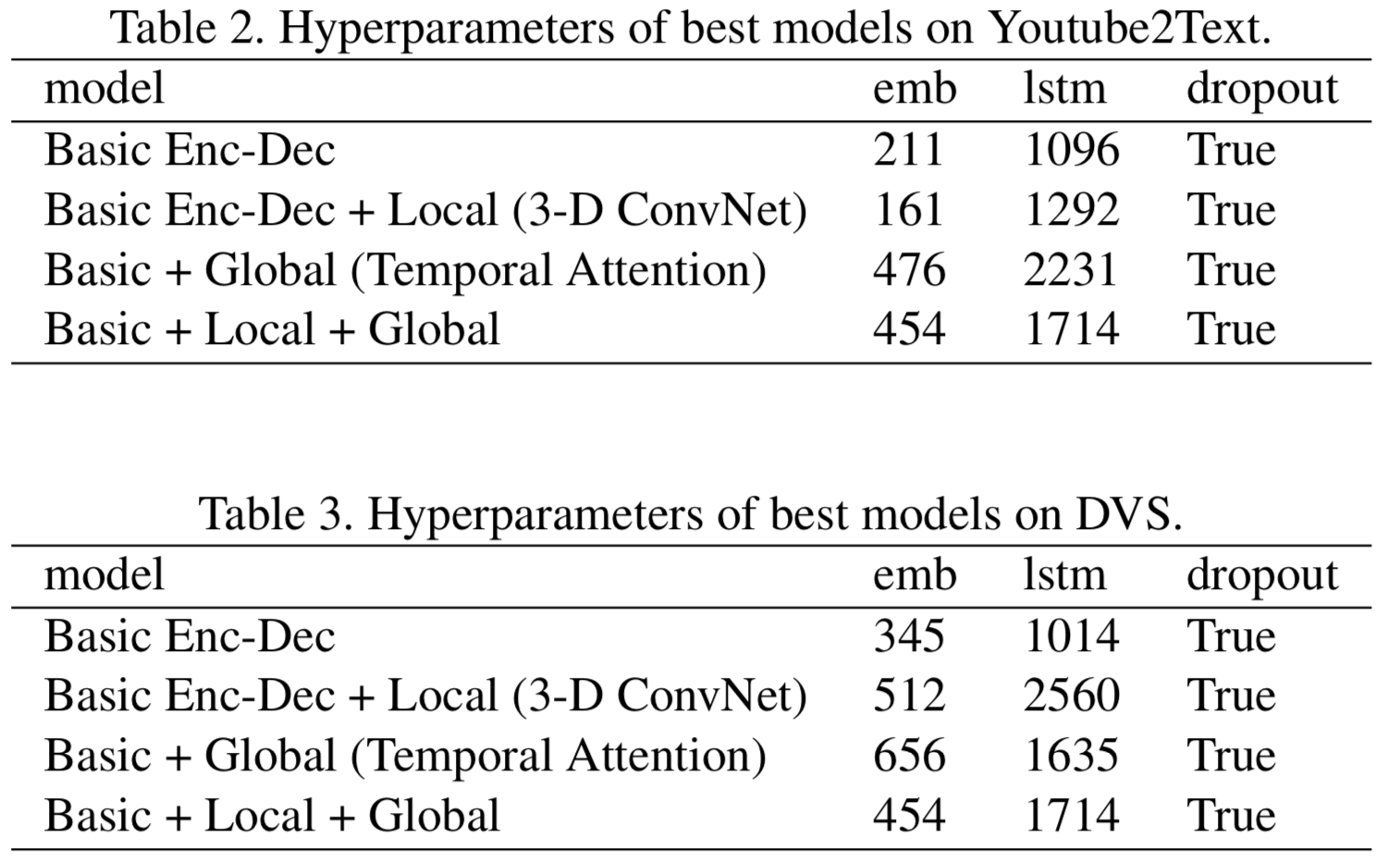
Experiment Details
Dataset
1970 YouTube video clips: each about 10 to 30 seconds, containing only one activity, with no dialogue. 1200 for training, 100 for validation, 670 for testing.
The dataset contains 49,000 video clips from 92 movies, and each video clip is annotated with descriptive sentences.
Evaluation Metrics
- BLEU

- METEOR

-
CIDER
-
Perplexity
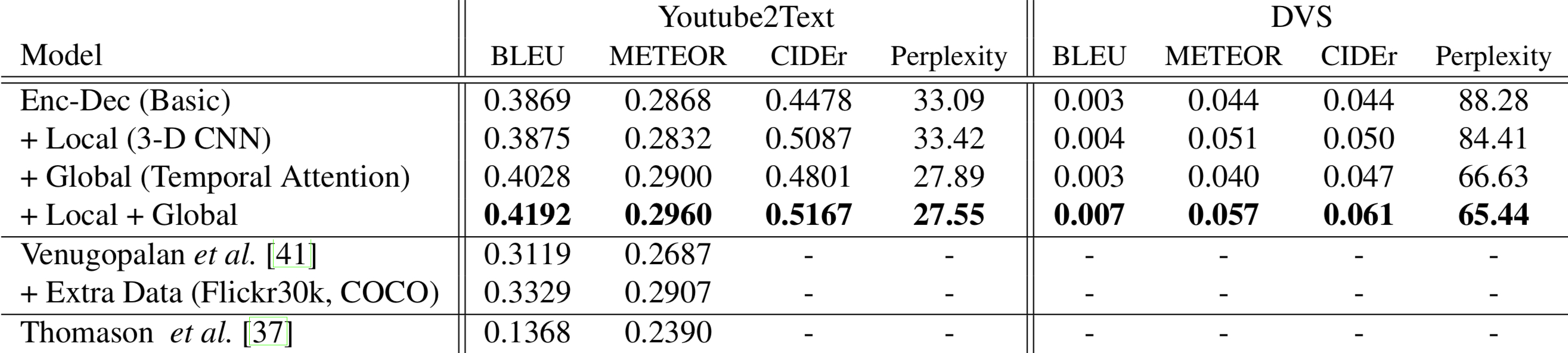
Experimental Results
- Experiment visualization

The bar chart represents the attention weight for each frame when generating each word of the corresponding color.
- Model comparison