Basic Paper Information
Paper Name: World Models
Paper Link: https://arxiv.org/pdf/1803.10122.pdf
Paper Source Code:
About Authors:
-
David Ha:
-
Jurgen Schmidhuber: Father of LSTM, needs no introduction
About Note Author:
- Zhu Zhengyuan, graduate student at Beijing University of Posts and Telecommunications, research direction is multimodal and cognitive computing.
Paper Recommendation Reason
By exploring and building generative neural network models of popular reinforcement learning environments. World models can be quickly trained in an unsupervised manner to learn compressed spatiotemporal representations of the environment. By using features extracted from the world model as input to the Agent, a very compact and simple policy can be trained to solve the required task. An Agent can even be trained entirely in the dream generated by its own world model, and transfer this policy back to the actual environment.
Background of the Era: A Predictable Winter, Yann LeCun
-
Deep learning lacks reasoning ability: common sense about the world and cognition of task background
-
Learning from scratch is really inefficient: deep learning needs a memory module (pre-training)
-
Self-supervised learning (Learn how to learn)
World Models
Paper Writing Motivation
Philosophical question: How do humans perceive the world? Humans gradually build their own mental model through limited perceptual abilities (eyes, nose, ears, skin). All human decisions and actions are generated based on predictions from each person’s internal model.
How do humans process information flow in daily life? By learning abstract representations of the temporal and spatial aspects of the objective world through attention mechanisms.
How does the human subconscious work? Taking baseball as an example, a batter needs to make a decision on when to hit the ball in such a short time (shorter than the time it takes for visual signals to reach the brain!). The reason humans can complete hitting is because the innate mental model can predict the ball’s trajectory.
Can we let models consciously build unique models for self-learning according to the environment?
Summary of Jurgen’s historical work: RNN-based world models in the context of reinforcement learning!
Model Details
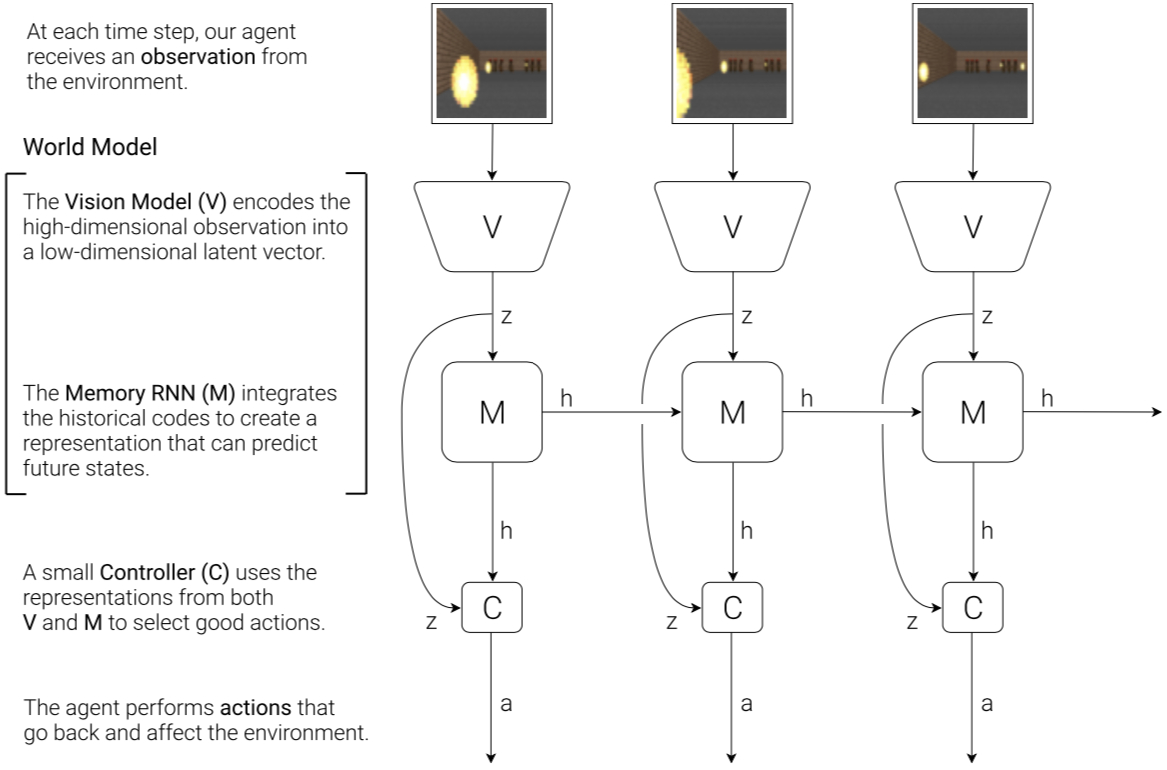
Overview of Agent Model
Visual perception component: compress visual information/environment representation
Memory component: predict the objective environment based on historical information
Decision module: select action strategy based on visual perception component and memory component
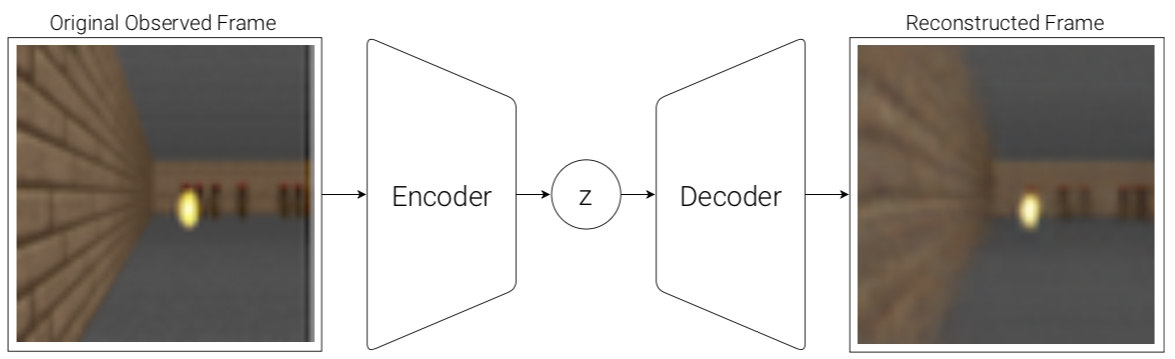
VAE(V) Model
The Agent can learn abstract, compressed representations from each frame observed through VAE.
MDN-RNN(M) Model
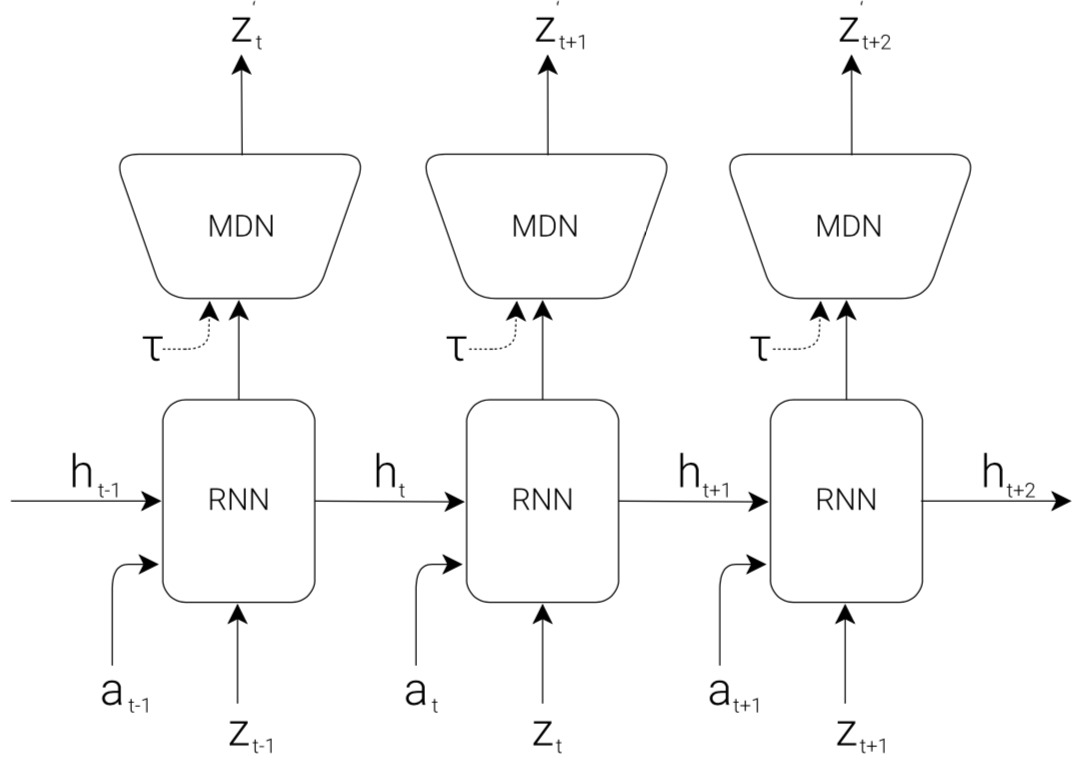
Where the prediction of the next moment $z*{t+1}$ is expressed in probability form as $P(z*{t+1}|a_t,z_t,h_t)$, where $a_t$ is the action at time $t$. And in the sampling stage, the model’s fuzziness is controlled by adjusting the temperature parameter $\tau$. (This parameter is very effective for subsequent training of controller $C$)
The MDN at the top of the model represents Mixture Density Network, outputting a Gaussian mixture model of the predicted z.
Controller(C) Model
This module is used to decide the Agent’s next action based on maximum cumulative Reward. The paper intentionally sets this module to be as small and simple as possible.
Therefore, the controller is a simple single-layer linear model: $$a_t=W_c[z_t h_t]+b_c$$
Specifically, the method to optimize controller parameters is not traditional gradient descent, but Covariance-Matrix Adaptation Evolution Strategy
Combining Three Modules
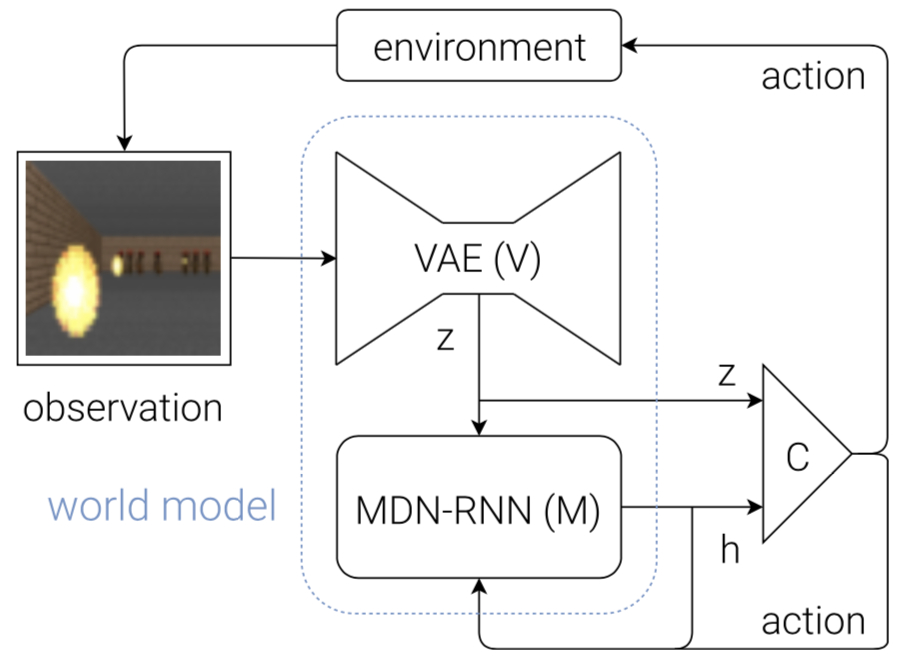
The flowchart below shows how $V$, $M$ and $C$ interact with the environment: First, at each time step $t$, the raw observation input is processed by $V$ to generate compressed $z(t)$. Then $C$‘s input is $z(t)$ and $M$‘s hidden state $h(t)$. Then $C$ outputs action vector $a(t)$ to affect the environment. $M$ takes the current moment’s $z(t)$ and $a(t)$ as input to predict the next moment’s hidden state $h(t+1)$.
In the code, there are many ways to input the $M$ module. I don’t quite agree with the diagram showing $C$‘s chosen action as also being input to $M$.
Representing the model through pseudocode:
1
2
3
4
5
6
7
8
9
10
11
12
def rollout(controller):
obs = env.reset()
h = rnn.initial_state()
done = False
cumulative_reward = 0
while not done:
z = vae.encode(obs)
a = controller.action([z, h])
obs, reward, done = env.step(a)
cumulative_reward += reward
h = rnn.forward([a, z, h])
return cumulative_reward
Experiment Design 1
Both experimental environments are selected from OpenAI Gym
Experimental Environment
CarRacing-v0(Car Racing Experiment)

The action space includes
-
Left turn
-
Right turn
-
Accelerate
-
Brake
Experiment Implementation Process
-
Collect 10,000 game processes based on random policies
-
Train VAE model based on each frame of each game process, output result is $z\in \mathcal{R}^{32}$
-
Train MDN-RNN model, output result is $P(z_{t+1}|a_t,z_t,h_t)$
-
Define controller (c), $a_t=W_c[z_t h_t]+b_c$
-
Use CMS-ES algorithm to obtain $W_b$ and $b_c$ that maximize cumulative Reward
Model parameters total:
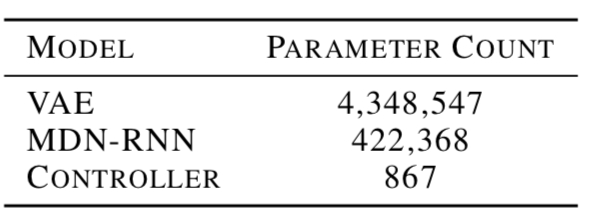
Experimental Results
Only adding V Model (VAE) If there is no M Model (MDN-RNN) module, the controller’s formula would be: $at=W{c}z_t+b_c$. Experimental results show this leads to unstable driving behavior by the Agent. In this case, trying to add a hidden layer to the controller, although the experimental results improved, still did not achieve very good results.
Complete world model (VAE+MDN-RNN) Experimental results show that the Agent drives more stably. Because $h_t$ contains the probability distribution of information about the future of the current environment, the Agent can make judgments as quickly as Formula 1 drivers and baseball players.
Comparison of world model with other models:
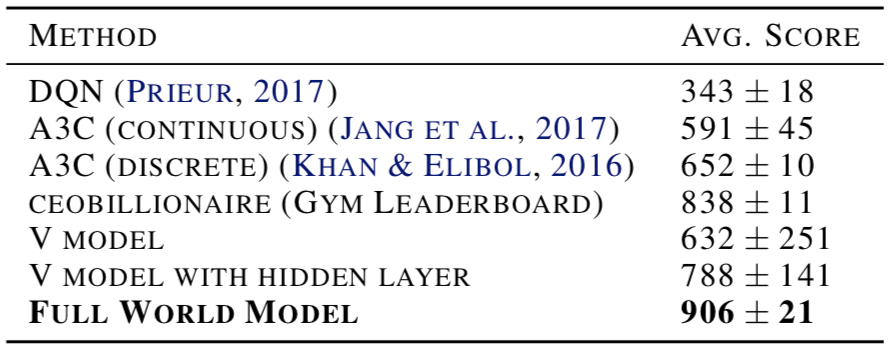
Visualize the current state $z_{t+1}$ of the world model

The above figure sets $\tau$ to 0.25 (this parameter can adjust the fuzziness of the generated environment)
Experiment Design 2
Can we let an Agent learn in its own dream and change its strategy for the real environment If the world model has a sufficient understanding of its purpose, then we can use the world model to replace the environment actually observed by the Agent. (Like when we go down stairs, we don’t need to carefully watch the stairs at all) Ultimately, the Agent will not directly observe the real world, but will only see what the world model allows it to see.
Experimental Environment
VizDoom Experiment
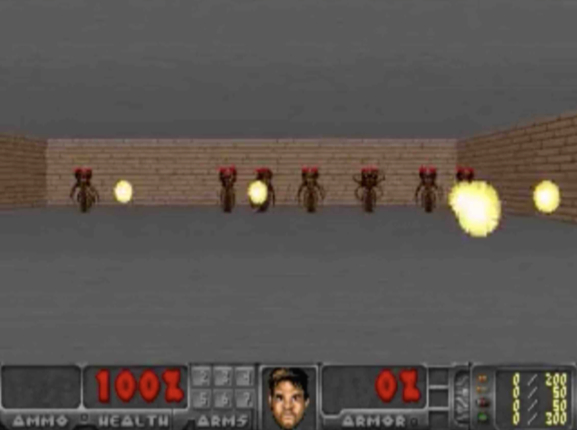
The game’s purpose is to control the Agent to avoid fireballs launched by monsters.
Experiment Implementation Process
The model’s M Model (MDN-RNN) is mainly responsible for predicting whether the Agent will die in the next moment (frame). When the Agent trains in its world model, the V Model is no longer needed to encode pixels of the real environment.
-
Select 10,000 games from random policies (same as experiment 1)
-
Train VAE model based on each frame of each game, obtain $z\in \mathcal{R}^{64}$ ($z$‘s dimension becomes 64), then use VAE model to convert collected images to latent space representation.
-
Train MDN-RNN model, output result is $P(z*{t+1},d*{t+1}|a_t,z_t,h_t)$
-
Define controller as $a_t=W_c[z_t h_t]$
-
Use CMA-ES algorithm to obtain $W_c$ that maximizes cumulative survival time from the virtual environment constructed by the world model
The model’s parameters total:
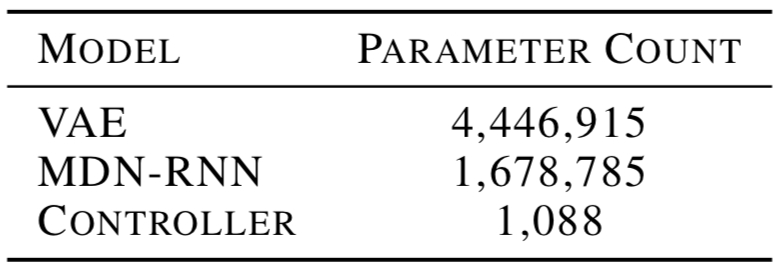
Blurring the World Model
By increasing the fuzziness parameter $\tau$, it will make the game more difficult (the environment generated by the world model is more blurry). If the Agent performs well with high fuzziness parameters, then it usually performs better in normal mode.
In other words, even if V model (VAE) cannot correctly capture all information of each frame, the Agent can still complete tasks given by the real environment.
Experimental results show that too low fuzziness parameters are equivalent to not using this parameter, but too high makes the model “nearsighted”. Therefore, a suitable fuzziness parameter value needs to be found.
Summary
Generalization: Iterative Training Procedure
-
Randomly initialize parameters of M Model (MDN-RNN) and C Model (Controller)
-
Conduct N trials on the real environment. Save the actions $a_t$ and observations $x_t$ of each trial
-
Train M Model (MDN-RNN), obtain $P(x*{t+1},r*{t+1},a*{t+1},d*{t+1}|x_t,a_t,h_t)$; Train C Model (Controller) and optimize expected rewards in M.
-
Return to step 2 if the task is not finished
The characteristic of this generalization procedure is that from M model, not only predicted observations $x$ and whether to end the task $done$ need to be obtained,
In general seq2seq models, they tend to generate safe, universal responses because such responses are more grammatically correct and appear more frequently in the training set, and the final generation probability is also highest, while meaningful responses often have smaller generation probabilities than them. By using MMI to calculate the dependency and correlation between input and output, the model’s generation probability for them can be reduced.
From Information to Memory: The Magic of the Hippocampus
Neuroscience research (2017 Foster) discovered the hippocampal replay phenomenon: when animals rest or sleep, their brains replay recent experiences. And the hippocampal replay phenomenon is very important for consolidating memory.
Attention: Only Care About Task-Related Features
Neuroscience research (2013 Pi) found that primary visual neurons are only activated from an inhibited state when rewarded. This suggests that humans typically learn from task-related features rather than all received features. (This conclusion holds true at least in adults)
Future Prospects
The current problem mainly appears in the M Model (MDN-RNN): limited by RNN model’s information storage capacity. The human brain can store memories for decades or even hundreds of years, but neural networks have difficulty training due to gradient vanishing.
If we want the Agent to explore more complex worlds, then future work may be to design a model that can replace the MDN-RNN structure, or develop an external memory module.

