Paper Basic Information
-
Paper Title: Object-Difference Attention: A Simple Relational Attention for Visual Question Answering
-
Paper Link: http://www.acmmm.org/2018/accepted-papers/
-
Source Code:
-
None
-
About Authors:
-
Wu Chenfei, Beijing University of Posts and Telecommunications AI Lab PhD
-
About Note Author:
-
Zhengyuan Zhu, Beijing University of Posts and Telecommunications graduate student, research direction: multimodal and cognitive computing.
Paper Recommendation Reason
Attention mechanisms have greatly promoted the development of Visual Question Answering (VQA) technology. Attention allocation plays a crucial role in attention mechanisms, weighting objects in images (such as image regions or bounding boxes) differently based on their importance in answering questions. Most existing work focuses on fusing image features and text features to calculate attention distribution, without comparing different image objects. As a main attribute of attention, discriminability depends on comparisons between different objects. This comparison provides more information for better attention allocation. To achieve object perceptibility, we propose an Object-Difference Attention (ODA) method that calculates attention probabilities by implementing difference operations between different image objects in images. Experimental results show that our ODA-based VQA model achieves state-of-the-art results. In addition, a general form of relational attention is proposed. Besides ODA, this paper also introduces some other related attention methods. Experimental results show that these relational attention methods have advantages on different types of questions.
Object Difference Attention Mechanism: A Simple Relational Attention Mechanism in Visual Question Answering
Introduction
Paper Terminology
-
Sequence encoding methods:
-
RNN: $y_t=f(y_{t-1},x_t)$
-
CNN: $y_t=f(x_{t-1},x_t,x_{t+1})$
-
Attention: $y_t=f(x_t, A, B), if A = B = X: Self Attention$
-
Examples of attention mechanisms $$Attention(Q,K,V)$$
-
Chronicle of attention mechanisms applied to VQA:
-
one-step linear fusion
-
multi-step linear fusion
-
bilinear fusion
-
multi-feature attention
-
Mutan mechanism
Paper Writing Motivation
- Most existing work focuses on fusing image features and text features to calculate attention distribution, while ignoring comparisons between different image objects.
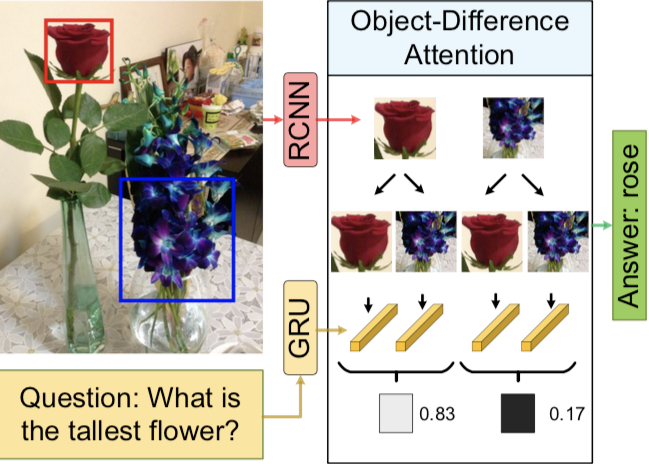
As shown above, to answer the question What is the tallest flower in the picture?, the model we build needs to focus not only on the potential answer rose, but also on orchid.
- How to reasonably allocate attention for existing problems?
Method to Solve the Problem
Rose Example
To answer What is the tallest flower in the picture?, how many steps are there?
-
Find all the flowers in the picture.
-
Compare the importance of different flowers for the correct answer.
The correct answer will be produced in the comparison process. Taking this example as inspiration, a new type of attention mechanism emerges: ODA calculates the attention distribution of objects in images by comparing each image object with all other objects under the guidance of questions.
Model Details
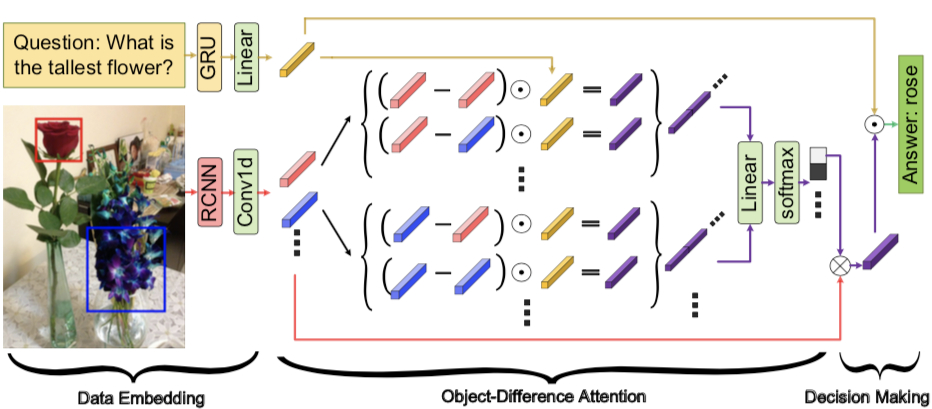
-
Embed data
-
$V^f=RCNN(image)$, where $v^f$ is an $m\times{d_v}$ dimensional embedding, representing $m$ boxes extracted.
-
$Q^f=GRU(question)$, where $Q^f$ represents the $d_q$ dimensional question embedding.
-
$V=relu(Conv1d(V^f))$
-
$Q=relu(Linear(Q^f))$
-
Object Difference Attention $$\hat{V}=softmax([(V_i-V_j)\odot{Q}]_{m\odot{md}}W_f)^{T}V$$ Advantages of this model:
-
Through comparison (difference), we can select more important objects.
-
Computational complexity is lower relative to traditional attention mechanism models (Mutan).
-
The “plug and play” characteristic makes this model very easy to apply to other domains.
-
Decision stage
-
Calculate $\hat{V}$ $p$ times and concatenate the results together. $$\hat{Z}=[\hat{V}^{1};\hat{V}^{2};…;\hat{V}^{p}]$$
Can refer to the multi-head in the Attention is all you need model
-
Combine image features and question features $$H=\sum^s_{s=1}(\hat{Z}W_v^{(s)}\odot{QW_q^{(s)}})$$
-
Prediction $$\hat{a}=\sigma(W_{h}H)$$
Extension: Relational Attention
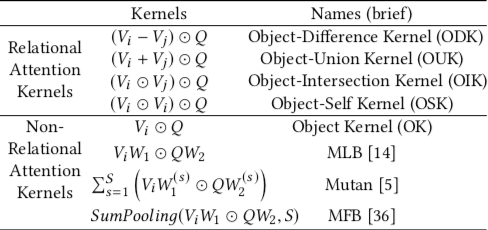
Expanding the $(V_i-V_j)\odot{Q}$ part of the model can yield different types of attention mechanisms
Experimental Results Analysis
Datasets
-
VQA1.0 dataset
-
VQA2.0 dataset
-
COCO-QA dataset
Evaluation Metrics
- For VQA1.0 and VQA2.0, use accuracy rate:

- For COCO_QA use:
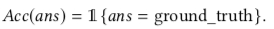
Experimental Result Evaluation
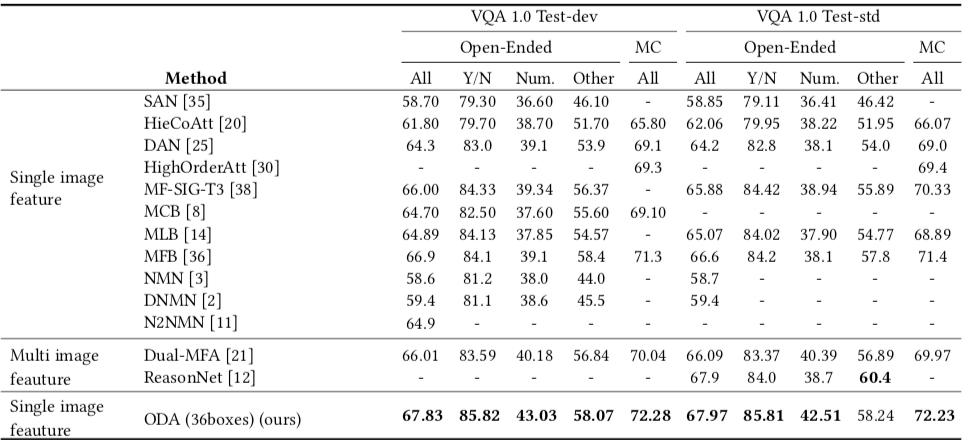
- Comparison with state-of-the-art models on VQA1.0
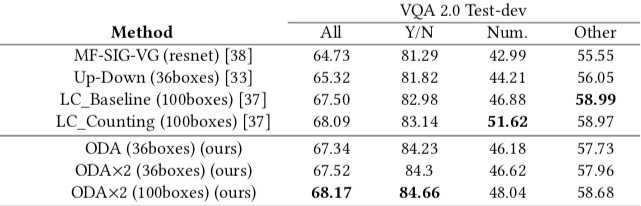
- Comparison with state-of-the-art models on VQA2.0
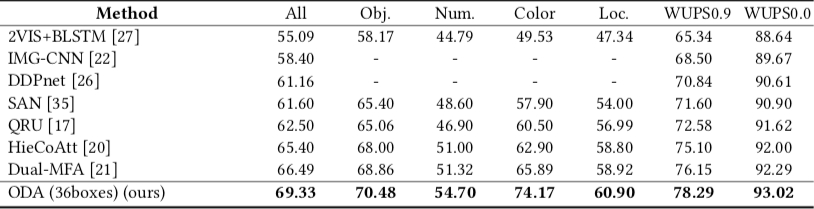
- Comparison with state-of-the-art models on VQA3.0
Conclusion
From an intuitive perspective, the object difference attention mechanism aligns with the human thinking process when answering questions based on images. Future research directions should be to build a world model through common sense knowledge about the world, reducing computational load and dependence on large amounts of labeled data through prior knowledge.

