Introduction
This note mainly references the original paper on variational autoencoders “Auto-Encoding Variational Bayes” and Su Shen’s blog
VAE Model
VAE’s goal (same as GAN): to construct a model that generates target data $X$ from latent variable $Z$. The core of VAE is: performing transformations between distributions.
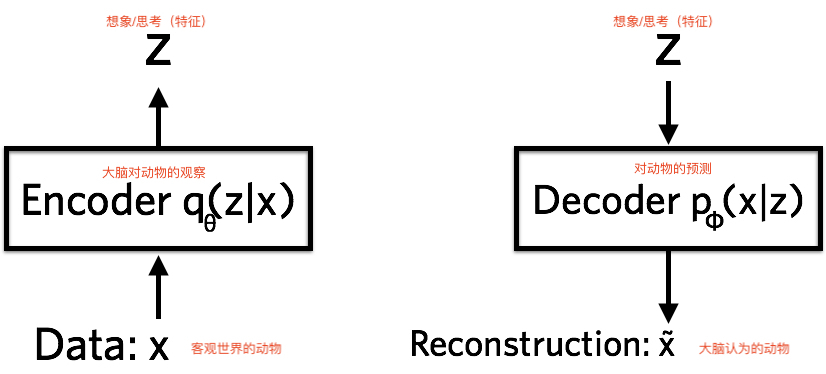
VAE has two Encoders, one to compute the mean and one to compute the variance.
The Problem
However, the difficulty of generative models is judging the similarity between the generated distribution and the true distribution. (That is, we only know the sampling results, not the distribution expressions)
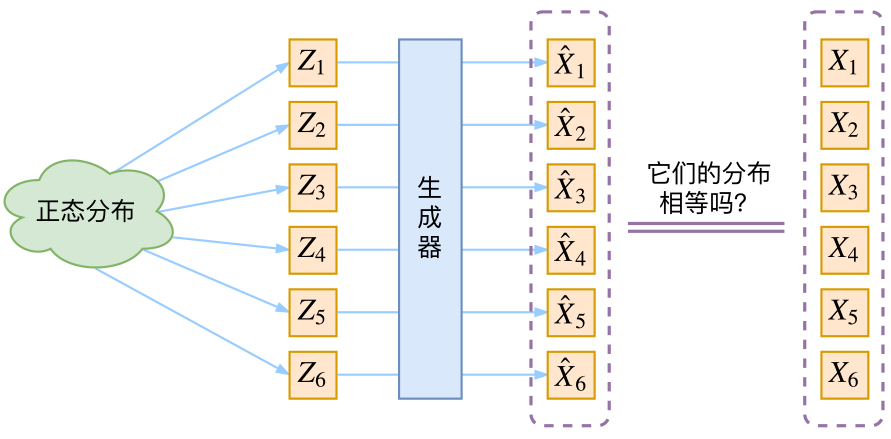
VAE as Described in Most Tutorials
The model’s approach is: first sample a Z from the standard normal distribution, then calculate an X based on Z. If the VAE structure is indeed this diagram, we actually have no idea: whether the $Z_k$ re-sampled still corresponds to the original $X_k$.
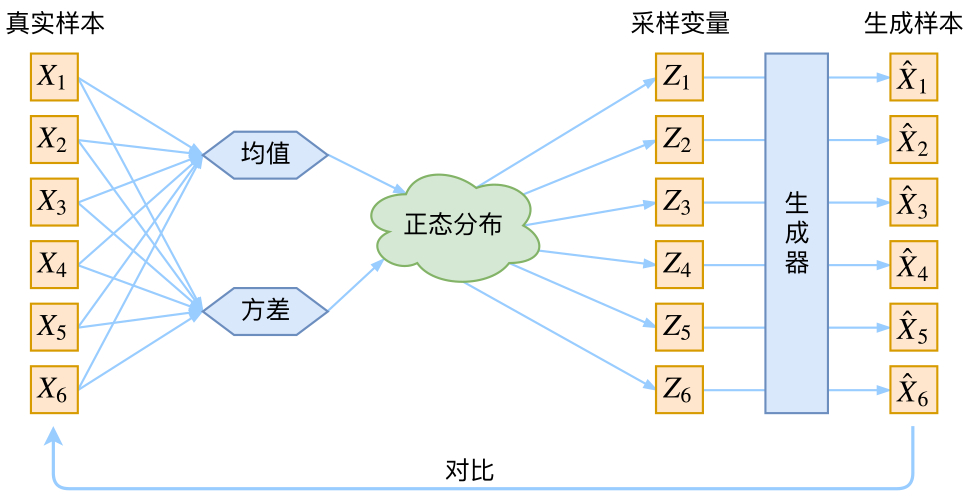
In fact, in the entire VAE model, we do not use the assumption that $p(Z)$ (distribution in latent variable space) is a normal distribution. We use the assumption that $p(Z|X)$ (posterior distribution) is a normal distribution!
However, the trained neural network And VAE makes all $P(Z|X)$ align with the standard normal distribution: $$p(Z)=\sum_X p(Z|X)p(X)=\sum_X \mathcal{N}(0,I)p(X)=\mathcal{N}(0,I) \sum_X p(X) = \mathcal{N}(0,I)$$
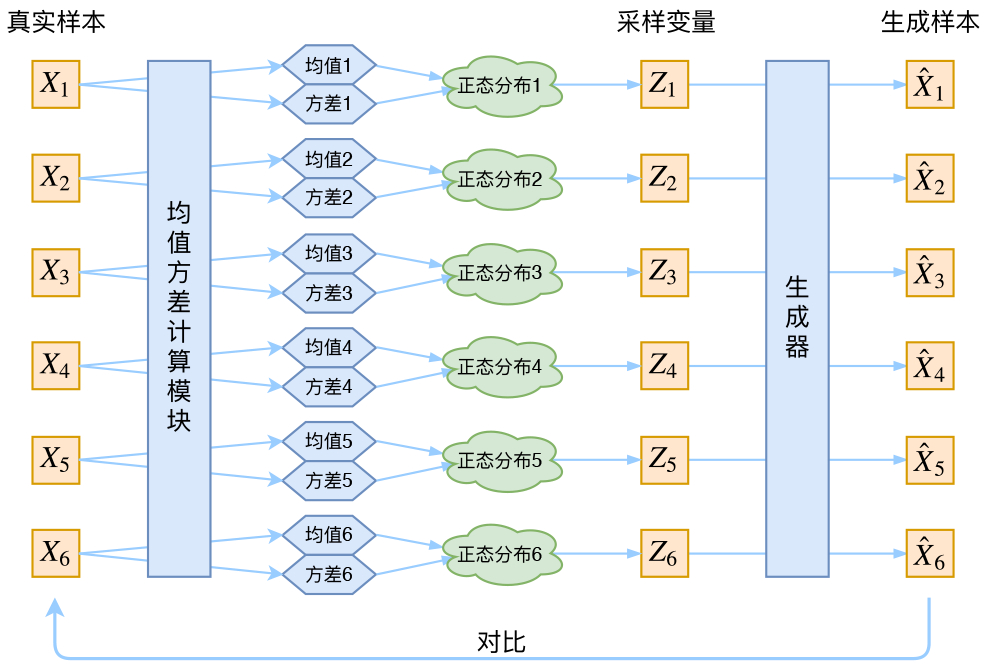
Real VAE
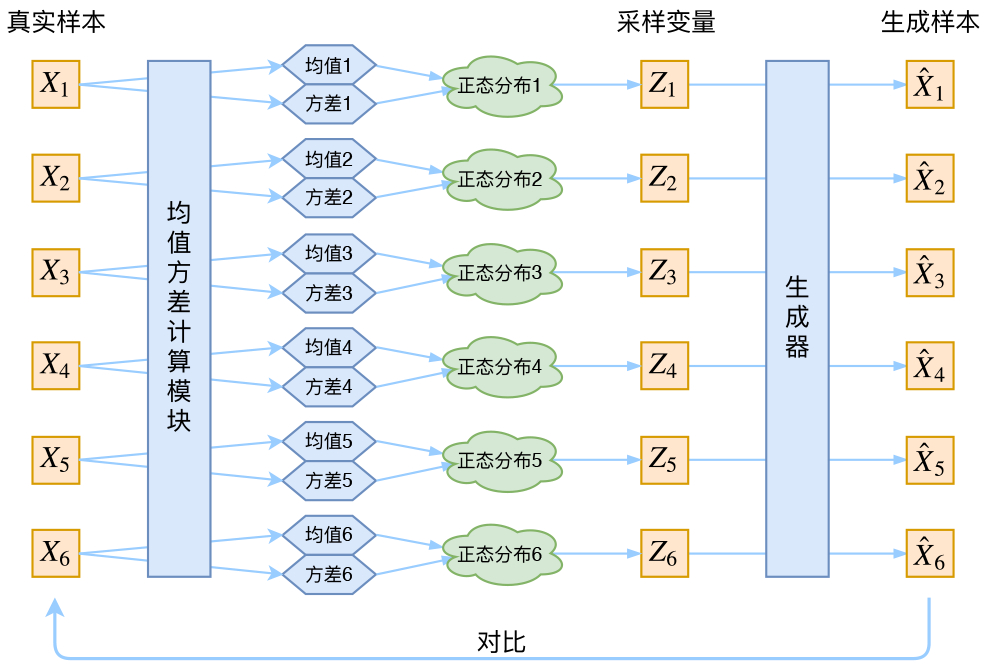
VAE constructs a dedicated normal distribution for each sample, then samples to reconstruct.
But the variance of the neural network after training will approach 0. Sampling will only get deterministic results.
Therefore, all normal distributions also need to align with the standard normal distribution (model assumption). To make all P(Z|X) align with $\mathcal{N}(0,I)$, we need:
Encoder: Use neural network method to fit parameters
Construct two neural networks: $\mu_k=f_1(Xk), log{\sigma^2}=f_2(X_k)$ to fit the mean and variance. When both are as close to zero as possible, the distribution also reaches $\mathcal{N}(0,I)$.
1
2
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)
For the selection of the ratio of the two losses, use KL divergence $KL(N(\mu,\sigma^2)||N(0,I))$ as an additional loss. The calculation result of the above formula is:
$$\mathcal{L}{\mu,\sigma^2}=\frac{1}{2} \sum{i=1}^d \Big(\mu*{(i)}^2 + \sigma*{(i)}^2 - \log \sigma_{(i)}^2 - 1\Big)$$
1
kl_loss = - 0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
Decoder: Ensure generation capability
Our ultimate goal is to minimize the error $\mathcal{D}(\hat{X_k},X_k)^2$.
The decoder’s process of reconstructing $X$ hopes to be noise-free, while $KL loss$ hopes to have Gaussian noise. The two are opposed. So, like GAN, VAE actually contains an adversarial process internally, except that they are mixed together and evolve together.
Reparameterization trick
In the process of backpropagation to optimize mean and variance, the “sampling” operation is not differentiable, but the result of sampling is differentiable.
Therefore, we can use $\epsilon$ sampled from the standard normal distribution to directly estimate $Z=\mu+\epsilon\times\sigma$.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def sampling(args):
"""Reparameterization trick by sampling fr an isotropic unit Gaussian.
# Arguments:
args (tensor): mean and log of variance of Q(z|X)
# Returns:
z (tensor): sampled latent vector
"""
z_mean, z_log_var = args
batch = K.shape(z_mean)[0]
dim = K.int_shape(z_mean)[1]
# by default, random_normal has mean=0 and std=1.0
epsilon = K.random_normal(shape=(batch, dim))
return z_mean + K.exp(0.5 * z_log_var) * epsilon
Thus, the “sampling” operation no longer participates in gradient descent; instead, the result of sampling participates, making the entire model trainable.
DEMO: Poetry Robot Based on CNN and VAE
Model Structure
First, each character is embedded as a vector, then stacked CNNs are used for encoding, then pooling to get an encoder result. Based on this result, the mean and variance are calculated, and then a normal distribution is generated and re-sampled. In the decoding stage, since there is only one encoder output result, but multiple characters need to be output, multiple different fully connected layers are first connected to get diverse outputs, and then more fully connected layers are added.
GCNN (Gated Convolutional Networks)
The CNN here is not ordinary CNN + ReLU, but GCNN proposed by Facebook. Essentially, it creates two different CNNs with the same shape, one without an activation function, and one activated with sigmoid. Then the results are multiplied together. This way, the sigmoid part acts as a “gate”.

