Note that the author is not Yoshua Bengio
Overview
In Seq2Seq sequence learning task, using Scheduled Sampling can improve performance of RNN model.
The ditribution bewteen traning stage and evaluating stage are different and reults in error accumulation question in evaluating stage.
The former methods deal with this error accumullation problem is Teacher Forcing.
Scheduled Sampling can solve the problem through take generated words as input for decoder in certain probability.
Note that scheduled sampling is only applied in training stage.
Algorithm Details
In training stage, when generate word $t$, Instead of take ground truth word $y_{t1}$ as input, Scheduled Sampling take previous generated word $g{t-1}$ in certain probability.
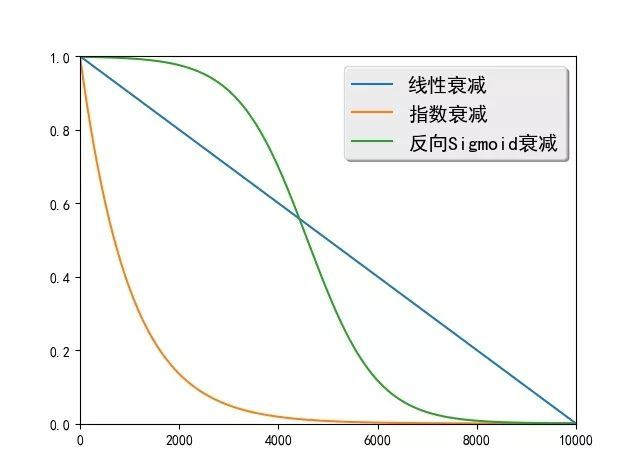
Assume that in $i_{th}$ mini-batch, Schduled Sampling define a probability $\epsilon_i$ to control the input of decoder. And $\epsilon_i$ is a probability variable that decreasing as $i$ increasing.
There are three decreasing methods: $$Linear Decay: \epsilon_i = max(\epsilon, (k-c)*i), where \epsilon restrict minimum of \epsilon_i, k and c controll the range of decay$$
Warning: In time step $t$, Scheduled Sampling will take $y_{t-1}$ according to $\epsiloni$ as input. And take $g{t-1}$ according to $1-\epsilon_i$ as input.
As a result, decoder will tend to use generated word as input.
Implementation
Parameters
1
2
3
4
parser.add_argument('--scheduled_sampling_start', type=int, default=0, help='at what epoch to start decay gt probability, -1 means never')
parser.add_argument('--scheduled_sampling_increase_every', type=int, default=5,help='every how many epochs to increase scheduled sampling probability')
parser.add_argument('--scheduled_sampling_increase_prob', type=float, default=0.05,help='How much to update the prob')
parser.add_argument('--scheduled_sampling_max_prob', type=float, default=0.25,help='Maximum scheduled sampling prob.')
Assign scheduled sampling probability
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# scheduled sampling probability is min(epoch*0.01, 0.25)
frac = (epoch - opt.scheduled_sampling_start) // opt.scheduled_sampling_increase_every
opt.ss_prob = min(opt.scheduled_sampling_increase_prob * frac, opt.scheduled_sampling_max_prob)
model.ss_prob = opt.ss_prob
# choose the word when decoding
if self.ss_prob > 0.0:
sample_prob = torch.FloatTensor(batch_size).uniform_(0, 1).cuda()
sample_mask = sample_prob < self.ss_prob
if sample_mask.sum() == 0: # use ground truth
last_word = caption[:, i].clone()
else: # use previous generated words
sample_ind = sample_mask.nonzero().view(-1)
last_word = caption[:, i].data.clone()
# fetch prev distribution: shape Nx(M+1)
prob_prev = torch.exp(log_probs.data)
last_word.index_copy_(0, sample_ind,
torch.multinomial(prob_prev, 1).view(-1).index_select(0, sample_ind))
last_word = Variable(last_word)
else:
last_word = caption[:, i].clone()
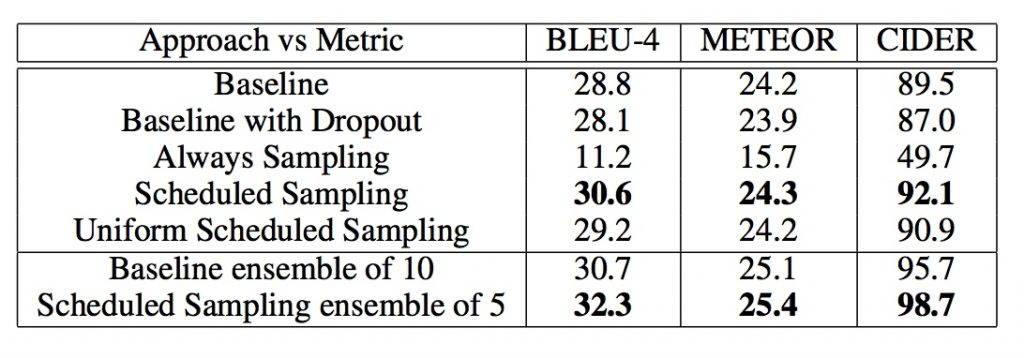
Result