Machine Learning
Basic knowledge
Bias and variance
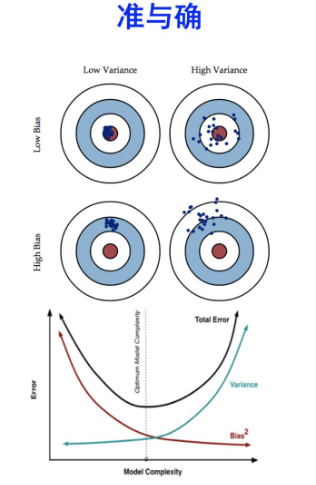
- Bias:
Represent fitting ability, a naive model will lead to high bias because of underfitting.
- Variance
Represent stability, a complex model will lead to high variance beacause of overfitting.
$$Generalization error = Bias^2 + Variance + Irreducible Error$$
Generative model and Discriminative Model
- Discriminative Model
Learn a function or conditional probability model P(X|Y)(posterior probability) directly.
- Generative Model
Learn a
joint probability model P(X, Y)then to calculateP(Y|X)
Search hyper-parameter
-
Grid search
-
Random search
Euclidean distance and Cosine distance
Example: A=[2, 2, 2] B=[5, 5, 5] represents two review scores of three movie.
the Euclidean distance is $\sqrt{3^2 + 3^2 + 3^2}$, and the Cosine distance is $1$. As a result, Cosine distance can avoid of difference
After normalization, essentially they are the same, $$D=(x-y)^2 = x^2+y^2-2|x||y|cosA = 2-2cosA,D=2(1-cosA)$$
Confusion Matrix

-
accuracy: $ACC = \frac{TP+TN}{TP+FN+FP+FN}$
-
precison: $P = \frac{TP}{TP+FP}$
-
recall: $R = \frac{TP}{TP+FN}$
-
F1: $F_1 = \frac{2TP}{2TP+FP+FN}$
deal with missing value
-
More missing value: drop feature column.
-
Less missing value: fill a value
-
Fill outlier:
data.fillna(0) -
Fill mean value:
data.fillna(data.mean())
Describe your project
-
Abstract reality to math problem
-
Describe your data
-
Proprocessing and feature selection
-
Model training and tuning
Algorithm
Logistic regreesion
Defination
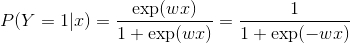
Loss: negative log los
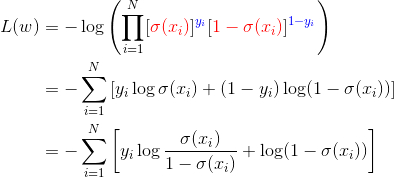
Support Vector Machine
Decision Tree
-
ID3: use
information gain -
C4.5: use
information gain rate
Ensemble Learning
Boosting: AdaBoost GBDT
Seiral strategy, new learning machine is based on previous one
GBDT(Gradient Boosting Decision Tree)
XGBoost
Bagging: Random forest and Dropout in Neural Network
Parallel strategy, no dependency between learning machines.
Deep Learning
Basic Knowledge
Overfitting and underfitting
Deal with overfitting
Data enhancement
-
image: translation, rotation, scaling
-
GAN: generate new data
-
NLP: generate new data via neural machine translation
Decrease the complexity of model
-
neural network: decrease layer numbers and neuron numbers
-
decision tree: decrease tree depth and pruning
Constrain weight:
-
L1 regularization
-
L2 regularization
Ensemble learning:
-
Neural network: Dropout
-
Decision tree: random forest, GBDT
early stopping
Deal with underfitting
-
add new feature
-
add model complexity
-
decrease regularization
Back-propagation TODO:https://github.com/imhuay/Algorithm_Interview_Notes-Chinese/blob/master/A-%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/A-%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9F%BA%E7%A1%80.md
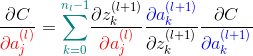
Superscript (l) represents the layer of the network, (L) represents the output layer (last layer); subscripts j and k indicate the position of neurons; w_jk represents the weight on the connection between the jth neuron in layer l and the kth neuron in layer (l-1)
MSE as loss function:
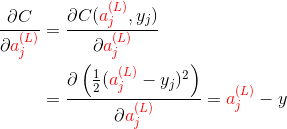
another expression:

Activation function: improve ability of expression
sigmoid(z)
$$\sigma(z)=\frac{1}{1+exp(-z)}, where the range is [0, 1]$$
the derivative of simoid is: TODO: to f(x) $$f’(x)=f(x)(1-f(x))$$
Batch Normalization
Goal: restrict data point to same distribution through normalization data before each layer.
Optimizers
SGD
Stochastic Gradient Descent, update weights each mini-batch
Momentum
Add former gradients with decay into current gradient.
Adagrad
Dynamically adjust learning rate when training.
Learning rate is in reverse ratio to the sum of parameters.
Adam
Dynamically adjust learning rate when training.
utilize first order moment estisourmation and second order moment estimation to make sure the steadiness.
How to deal with L1 not differentiable
Update parameters along the axis direction.
How to initialize the neural network
Init network with Gaussian Distribution or Uniform Distribution.
Glorot Initializer: $$W_{i,j}~U(-\sqrt{\frac{6}{m+n}}, \sqrt{\frac{6}{m+n}})$$
Computer Vision
Models and History
-
2015 VGGNet(16/19): Very Deep Convolutional Networks for Large-Scale Image Recognition, ICLR 2015.
-
2015 GoogleNet:
-
2016 Inception-v1/v2/v3: Rethinking the Inception Architecture for Computer Vision, CVPR 2016.
-
2016 ResNet: Deep Residual Learning for Image Recognition, CVPR 2016.
-
2017 Xception: Xception: Deep Learning with Depthwise Separable Convolutions, CVPR 2017.
-
2017 InceptionResNet-v1/v2、Inception-v4
-
2017 MobileNet: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, arXiv 2017.
-
2017 DenseNet: Densely Connected Convolutional Networks, CVPR 2017.
-
2017 NASNet: Learning Transferable Architectures for Scalable Image Recognition, arXiv 2017.
-
2018 MobileNetV2: MobileNetV2: Inverted Residuals and Linear Bottlenecks, CVPR 2018.
Basic knowledge
Practice experience
Loss function decline to 0.0000
Because of overflow in Tensorflow or other framework. it is better to initialize parameters in a reasonable interval. The solution is Xavier initialization and Kaiming initialization.
Do not normaolize the bias in neural network
That will lead to underfitting because of sparse $b$
Do not set learning rate too large
When using Adam optimizer, try $10^{-3}$ to $10^{-4}$
Do not add activation before sotmax layer
Do not forget to shuffle training data
For the sake of overfitting
Do not use same label in a batch
For the sake of overfitting
Do not use vanilla SGD optimizer
Avoid getting into saddle point
Please checkout gradient in each layer
For the sake of potential gradient explosion, we need to use gradient clip to cut off gradient
Please checkout your labels are not random
Problem of classification confidence
Symptom: When losses increasing, but the accuracy still increasing
For the sake of confidence: [0.9,0.01,0.02,0.07] in epoch 5 VS [0.5,0.4,0.05,0.05] in epoch 20.
Overall, this phenomenon is kind of overfitting.
Do not use batch normalization layer with small batch size
The data in batch size can not represent the statistical feature over whole dataset。
Set BN layer in the front of Activation or behind Activation
Improperly Use dropout in Conv layer may lead to worse performance
It is better to use dropout layer in a low probability such as 0.1 or 0.2.
Just like add some noise to Conv layer for normalization.
Do not initiate weight to 0, but bias can
Do not forget your bias in each FNN layer
Evaluation accuracy better than training accuracy
Because the distributions between training set and test set have large difference.
Try methods in transfer learning.
KL divergence goes negative number
Need to pay attention to softmax for computing probability.

