Reinforcement learning notes for undergraduate graduation project. Many reinforcement learning terms can be ambiguous when expressed in Chinese, so this note uses English. David Silver Reinforcement Learning Course Video David Silver Reinforcement Learning Course Materials.
Lecture One
Abstract
-
all is about decision
-
no supervisor,only reward signal(not supervisor learning)
-
feedback is delayed,not instantaneous
-
the key role:agent(brain)
The process
-
background:environment(earth) input: observation & reward –> output:action
-
history and state: History: $$H_t=A_1,O_1,A_2,O_2…A_t,O_t,R_t$$ State of agent : $$S_t^a=f(H_t)$$ State of environment: $$S_t=f(H_t)$$
Markov Reward Process
A Markov reward process is a Markov chain with values.(State,Probability,Reward,Discount factor-gamma)

return(G)
the return G is the total discounted reward from time-step t.
$$G_t = R_{t+1}+{\gamma}R_{t+2}+ {\gamma} ^2R_{t+3}…+{\gamma}^kR_{t+k+1}$$ we could figure out from equation above if discount factor closes to 0 the return will be “myopic”, if discount factor nevertheless closes to 1 then the return will be “far-sighted”
Value Function:Expectation
the value function v(s) gives the long-term value of state s.
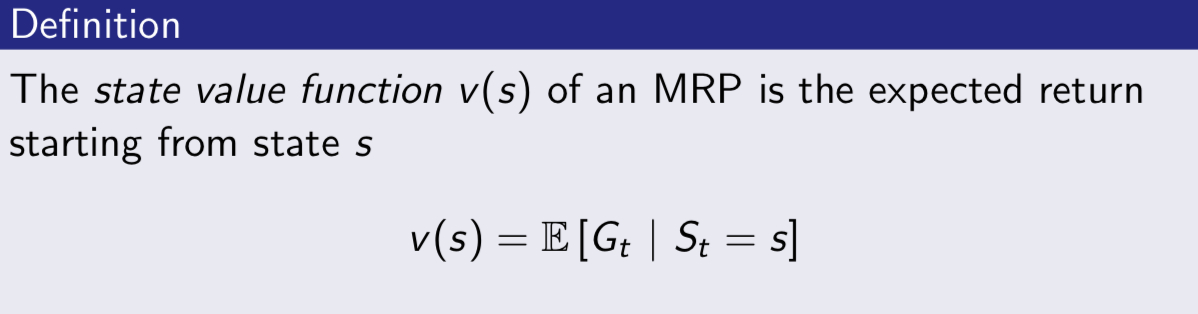
then we could deduce MRP Bellman Equation below:
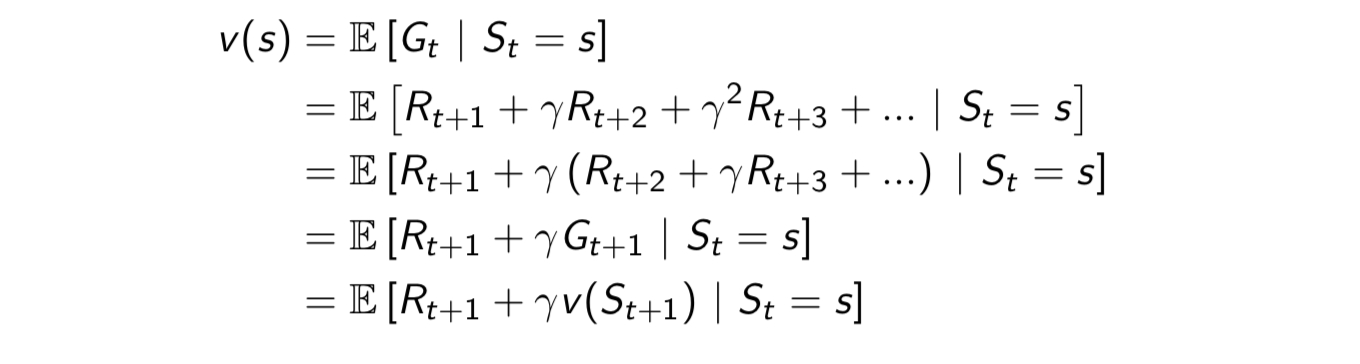
Reward only relates to state,therefore Bellman Equation can be decomposition said by:
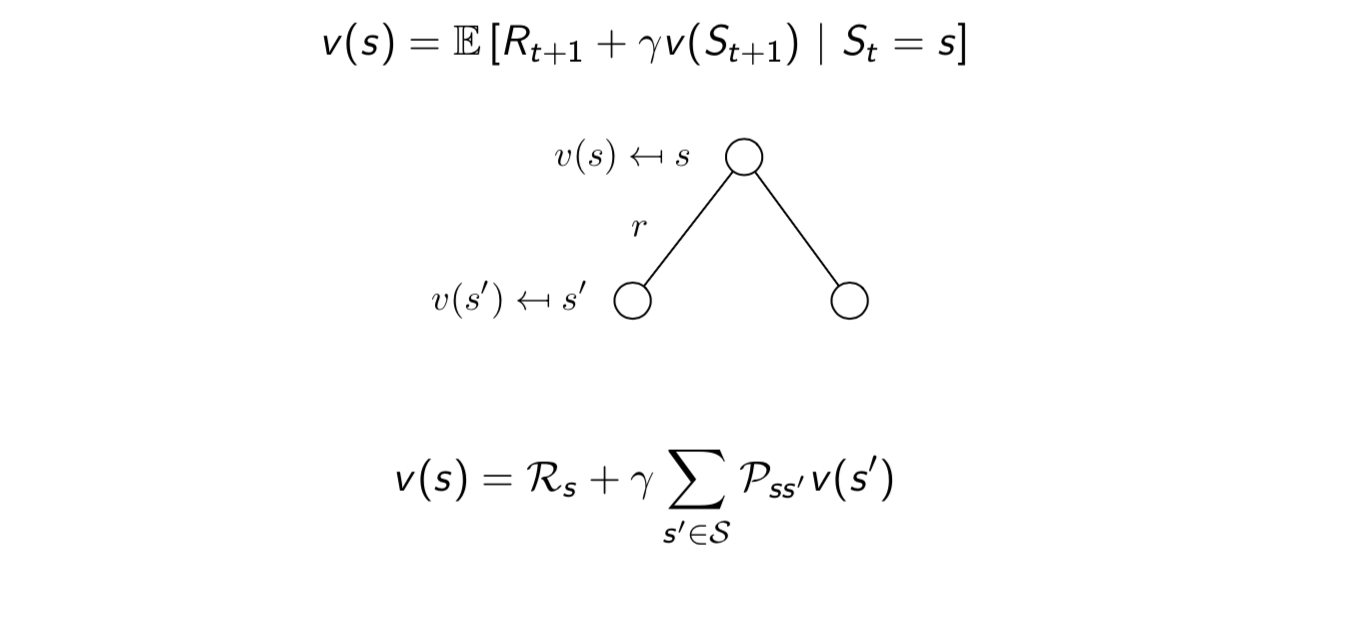
Bellman Equation for MRPs in matrix:
The bellman equation can be expressed concisely using matrics:

The bellman equation is a kind of linear equation so we could solve it directly:
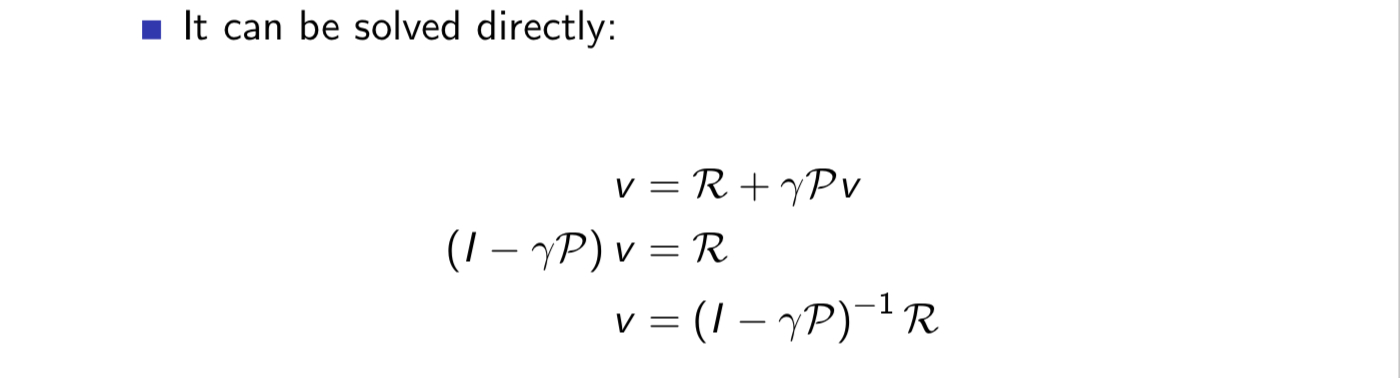
But time complexity is close to $O(n^3)$,we could solve it by iteration methods:
-
Dynamic Programming
-
Monto Carlo evaluation
-
Temporal-Difference(TD) Learning
Let us see some other concepts for preparing!
Markov Decision Processes
Markov Decison Processes (S,A,P,R,$\gamma$) is a Markov Reward Processed with decisons.It is an environment in which all states are Markov

Policies
A policy $\pi$ is a distribution over actions given states.
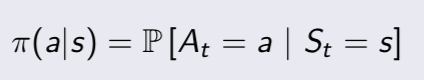
for MDP, we must calculate state-value function and action-value function, we have definition below:

just like bellman equation, we could deduce bell expectation equation from state-value function and action-value function:

we finally have different Bellman Expectation Equation for $V^{\pi}$,$Q^{\pi}$ and the Matrix Form is:

Optimal Value Functions
Coming question, how could we judge the performance of our policy?

Optimal Bellman Equation
we could deduce the Optimal Bellman Eqution from above first:
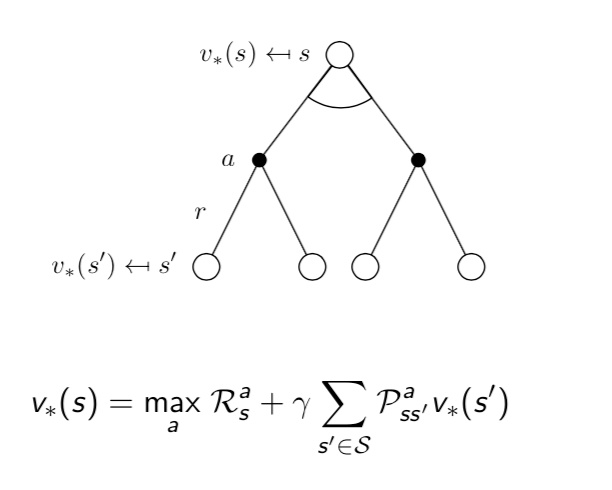
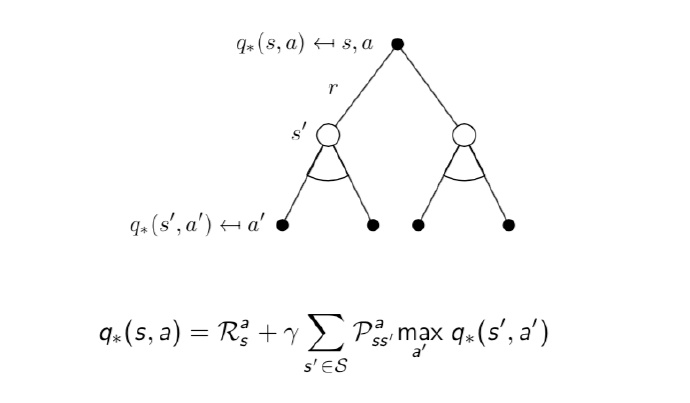
we could solve the equation by:
-
Value iteration
-
Police iteration
-
Q-Learning
-
Sarsa
extension of MDP
-
infinite MDPS
-
Reductions of POMDP’s
infinite MDPs

POMDP:
It could be seen as a Hidden Markov Process adding actions!

Let us review immediately!


Lecture 3 : Planning by Dynamic Programming
Introduction
-
Dynamic sequential or temporal component to the problem
-
Programming is a optimision of question!
-
optimal substructure
-
overlapping subproblems
There are two applications of DP
for prediction:
-
Input:MDP & policy $\pi$
-
Output: value function $v_\pi$
for control
-
Input: MDP
-
Output: optimal value function $v_$ & optimal policy $\pi_$

Iterative Policy Evaluation
How to evaluate $\pi$?
-
solition:iterative application of bellman expectation backup to get the true value function($V_0->V_\pi$)
-
from end to start by iteration.
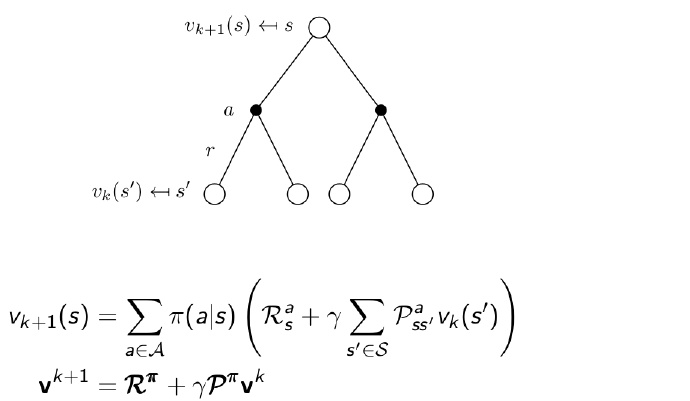
It is just like a weighted average of every probability of each action.
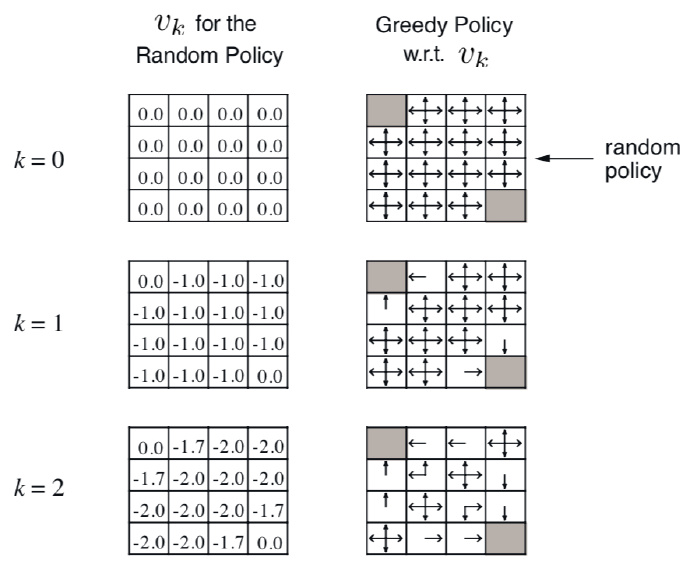
the detail you could see the manuscript!

Policy Iteration:
-
evaluate the policy $\pi$:fill the maze with number to get $v_\pi$ $$V_\pi(s) = E[R_{t+1}+\gamma R_{t+2}+…|S_t = s]$$
-
improve the policy by acting greedy with respect to $v_\pi$ $$\pi^{’} = greedy(v_\pi) $$
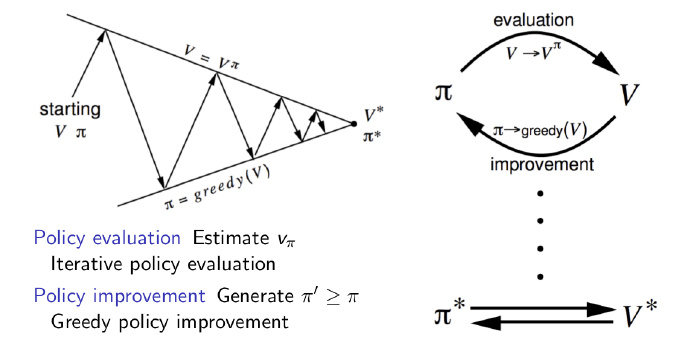
- Policy improvement:

the details you could see the manuscript!
Value Iteration
The solution v∗(s) can be found by one-step lookahead, and it start with final rewards and work backwards:

There is an example:
the details you could see the manuscript!
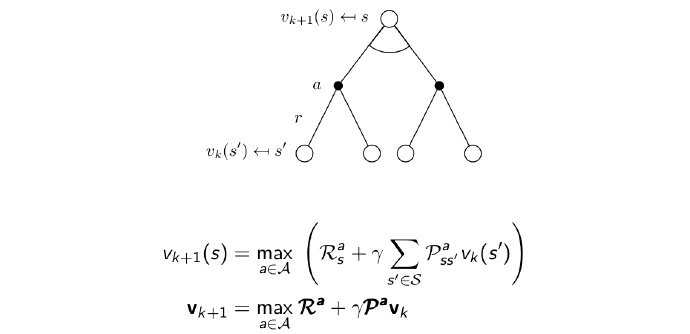
Synchronous Dynamic Programming Algorithms
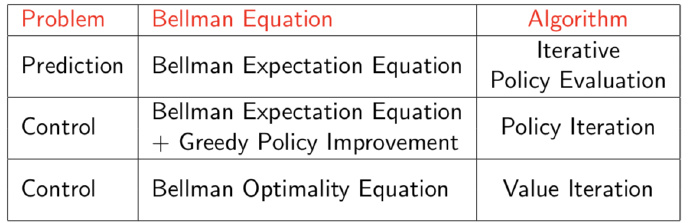
we could see Iterative Policy Evaluation and Policy Iteration as a whole knowledge. The knowledge is all in consideration of policy.They as the same in essence.
Asynchronous Dynamic Programming
- In-Place Dynamic Programming

the main difference between two methods above is the number of copy for reducing storage.
- Prioritised sweeping

- Real-time dynamic programming


