Paper Basic Information
-
Paper Title: A Diversity-Promoting Objective Function for Neural Conversation Models
-
Paper Link: https://arxiv.org/pdf/1510.03055.pdf
-
Source Code:
-
None
-
About Authors:
-
Jiwei Li: Stanford University PhD graduate, citation count as of publication: 2156
-
About Note Author:
-
Zhengyuan Zhu, Beijing University of Posts and Telecommunications graduate student, research direction: multimodal and cognitive computing.
Paper Recommendation Reason
The paper proposes using Maximum Mutual Information (MMI) instead of the original Maximum Likelihood as the objective function, aiming to use mutual information to reduce the generation probability of boring responses like “I don’t Know”.
A Diversity-Promoting Objective Function for Neural Conversation Models
Background Knowledge
- Seq2Seq Model:
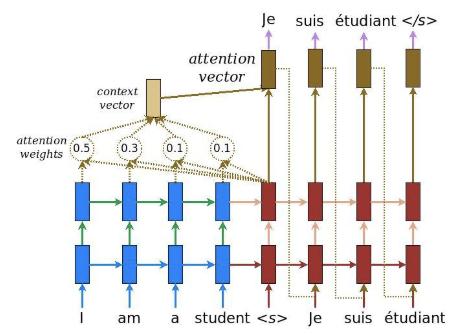
Paper Writing Motivation
More and more researchers are beginning to explore data-driven dialogue generation methods. They are mainly divided into three schools:
-
Phrase-based statistical methods (Ritter 2011): Traditional phrase-based translation systems complete tasks by dividing source sentences into multiple blocks and then translating them sentence by sentence.
-
Neural network methods
-
Seq2Seq models (Sordoni 2015)
Seq2Seq neural network models generate responses that are often very conservative. (I don’t know)
Problem Solution Approach
Maximum Mutual Information Model
-
Symbol representation
-
$S={s_1, s_2, …, S_{N_s}}$: Input sentence sequence
-
$T={t_1, t_2, …, t_{N_s}, EOS}$: Target sentence sequence, where $EOS$ indicates end of sentence.
-
MMI evaluation criteria
-
MMI-antiLM: For the standard objective function:
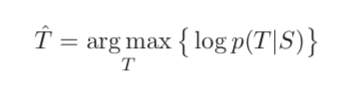
Improved to:
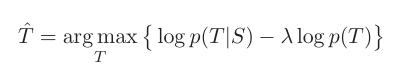
On the basis of the original objective function, the probability of the target sequence itself $logp(T)$ is added. $p(T)$ is the probability of a sentence existing, which is also a model. The lambda in front is a penalty factor. The larger it is, the greater the penalty on the language model. Since a minus sign is used here, it is equivalent to subtracting the probability of the language model from the original target, which also reduces the occurrence probability of high-frequency sentences like “I don’t know”.
- MMI-bidi: On the basis of the standard objective function, $logp(S|T)$ is added, which is the probability of producing S on the basis of T. The importance of the two can be measured by changing the size of lambda. The latter can represent the probability of producing input when responding to the input model. Naturally, the probability of an answer like “I don’t know” will be relatively low. Since addition is used here, it will reduce the probability of this type of response.
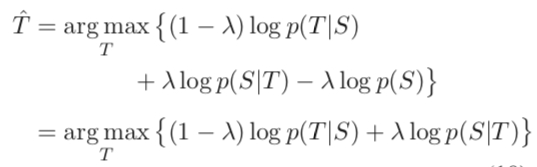
MMI-antiLM
As mentioned above, the MMI-antiLM model uses the first objective function, introducing $logp(T)$. If lambda is not chosen appropriately, it may cause the generated response to not conform to the language model, so corrections are made during actual use. Since during the decoding process, the first word or first few words are usually selected based on the encode vector, and later words tend to be selected based on previously decoded words and the language model, while the influence of encode information is smaller. That is to say, we only need to penalize the first few words, and later words can be directly selected according to the language model, so that the entire sentence will not violate the language model. Use $U(T)$ in the following formula to replace $p(T)$, where $g(k)$ indicates the sentence length to be penalized:
In addition, we also want to add the factor of response sentence length as a basis for model response, so the above objective function is corrected to the following formula:
MMI-bidi
The MMI-bidi model introduces the $p(S|T)$ term, which requires calculating the complete T sequence first and then passing it into a pre-trained backward seq2seq model to calculate the value of this term. But considering that the S sequence will generate countless possible T sequences, we cannot calculate every T, so beam-search is introduced here to only calculate the top 200 sequences T as a substitute. Then calculate the sum of the two terms and perform score re-ranking. The paper also mentions the shortcomings of doing this, such as the final effect depending on the effect of the selected top N sequences, etc., but the actual effect is still acceptable.
Experimental Design
Dataset
-
Twitter Conversation Triple Dataset: Contains 23 million dialogue fragments.
-
OpenSubtitiles Dataset
Comparison Experimental Methods:
-
SEQ2SEQ
-
SEQ2SEQ(greedy)
-
SMT(statistical machine translation): 2011
-
SMT + neural reranking: 2015
Evaluation Metrics
-
BLEU
-
distinct-1
-
distinct-2
Experimental Results Analysis
Experimental Result Evaluation
Finally, tests were conducted on both Twitter and OpenSubtitle datasets. The effectiveness shows BLEU scores are better than standard seq2seq models.
- OpenSubtitle
Conclusion
General seq2seq models tend to generate safe, universal responses because such responses are more in line with grammatical rules, appear more frequently in the training set, and ultimately have the highest generation probability, while meaningful responses often have lower generation probability than them. By using MMI to calculate the dependence and correlation between input and output, the model’s generation probability for them can be reduced.

