Introduction to demo
Source Code:image_captioning_with_attention
Related Papers
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.
Goal of this end2end model
- Generate a caption, such as “a surfer riding on a wave”, according to an image.

- Use an attention based model that enables us to see which parts of the image the model focuses on as it generates a caption.
Dateset
MS-COCO:This dataset contains >82,000 images, each of which has been annotated with at least 5 different captions.
Frame work of demo:
-
Download and prepare the MS-COCO dataset
-
Limit the size of the training set for faster training
Preprocess the images using InceptionV3: extract features from the last convolutional layer.
-
Initialize InceptionV3 and load the pretrained Imagenet weights
-
Caching the features extracted from InceptionV3
Preprocess and tokenize the captions
-
First, tokenize the captions will give us a vocabulary of all the unique words in the data (e.g., “surfing”, “football”, etc).
-
Next, limit the vocabulary size to the top 5,000 words to save memory. We’ll replace all other words with the token “UNK” (for unknown).
-
Finally, we create a word –> index mapping and vice-versa.
-
We will then pad all sequences to the be same length as the longest one.
create a tf.data dataset to use for training our model.
Model
-
extract the features from the lower convolutional layer of InceptionV3 giving us a vector of shape (8, 8, 2048).
-
This vector is then passed through the CNN Encoder(which consists of a single Fully connected layer).
-
The RNN(here GRU) attends over the image to predict the next word.
Training
-
We extract the features stored in the respective .npy files and then pass those features through the encoder.
-
The encoder output, hidden state(initialized to 0) and the decoder input (which is the start token) is passed to the decoder.
-
The decoder returns the predictions and the decoder hidden state.
-
The decoder hidden state is then passed back into the model and the predictions are used to calculate the loss.
-
Use teacher forcing to decide the next input to the decoder.
-
Teacher forcing is the technique where the target word is passed as the next input to the decoder.
-
The final step is to calculate the gradients and apply it to the optimizer and backpropagate.
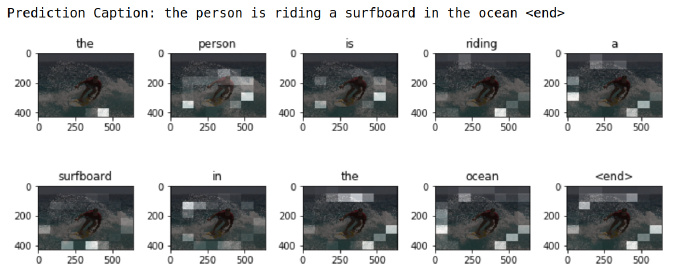
Caption
-
The evaluate function is similar to the training loop, except we don’t use teacher forcing here. The input to the decoder at each time step is its previous predictions along with the hidden state and the encoder output.
-
Stop predicting when the model predicts the end token.
-
And store the attention weights for every time step.
Problems undesirable
Version
-
The code requires TensorFlow version >=1.9. 1.10.0 is better.
-
cudatoolkit

