Paper Basic Information
-
Paper Title: Visual Question Answering: Datasets, Algorithms, and Future Challenges
-
Paper Link: https://arxiv.org/pdf/1610.01465.pdf
-
Source Code
-
None
-
About Authors
-
Kushal Kafle
-
Christopher Kanan
-
About Note Author:
-
Zhengyuan Zhu, Beijing University of Posts and Telecommunications graduate student, research direction: multimodal and cognitive computing.
Paper Recommendation Reason
Visual Question Answering (VQA) is a hot topic in recent years in the fields of computer vision and natural language processing. In VQA, an algorithm needs to answer text-based questions about images. Since the release of the first VQA dataset in 2014, more datasets have been released and many algorithms have been proposed. In this review, we critically examine the current state of VQA from the perspectives of problem formulation, existing datasets, evaluation metrics, and algorithms. In particular, we discuss the limitations of current datasets in properly training and evaluating VQA algorithms. Then, we exhaustively review existing algorithms for VQA. Finally, we discuss possible directions for future VQA and image understanding research.
Visual Question Answering: Datasets, Algorithms, and Future Challenges
Introduction
Research Value of VQA
-
Most computer vision tasks cannot fully understand images Image classification, object detection, action recognition and other tasks are difficult to obtain spatial location information of objects and perform reasoning based on their attributes and relationships.
-
Human obsession with the pursuit of Grand Unified Theory
-
Object recognition task: What is in the image? [classification]
-
Object detection task: Is there a cat in the image? [bounding box]
-
Attribute classification task: What color is the cat in the image?
-
Scene classification: Is the image indoors?
-
Counting task: How many cats are in the image?

-
Pass the visual Turing test:
-
Benchmark question testing
-
Establish evaluation metrics
VQA Datasets
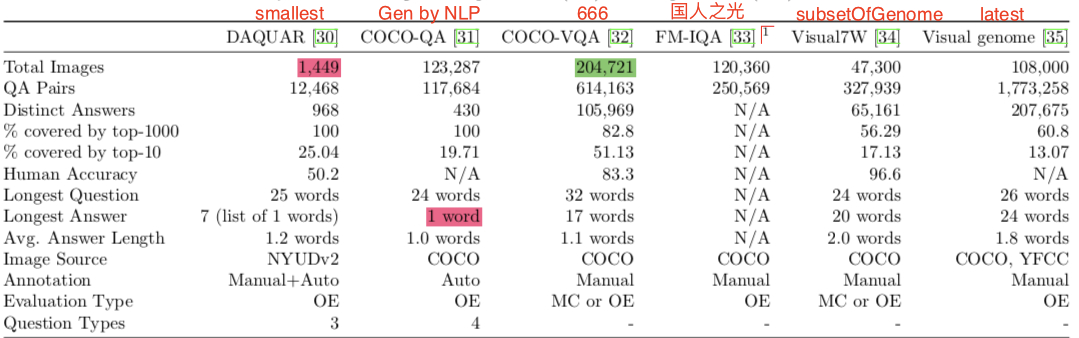
VQA Evaluation Criteria
-
Open-ended (OE): Open-ended
-
Multiple Choice (MC): Multiple choice
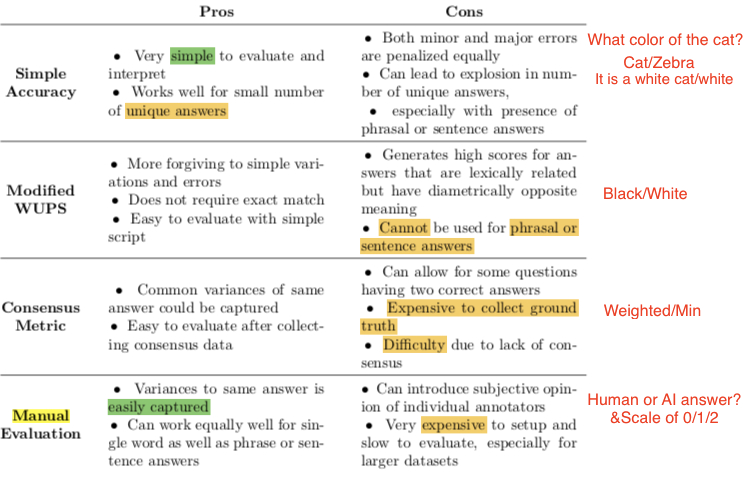
Popular Evaluation Criteria
The evaluation criterion for multiple-choice tasks can directly use accuracy. But what about the evaluation criterion for open-ended tasks?
-
Simple accuracy:
-
Q: What animals are in the photo If
dogsis the correct answer, thendogandzebrahave the same penalty -
Q: What is in the tree If
bald eagleis the correct answer,eagleorbirdversusyesalso have the same penalty -
Wu-Palmer Similarity
-
Semantic similarity The
WUPS scoreof the wordsBlackandWhiteis 0.91. So this may give a fairly high score to incorrect answers. -
Can only evaluate words, cannot be used for sentences
-
$Accuracy_{VQA}=min(\frac{n}{3}, 1)$ Also semantic similarity, approximately correct is ok: manually construct an answer set, $n$ is the number of same answers the algorithm and humans have.
VQA Algorithms
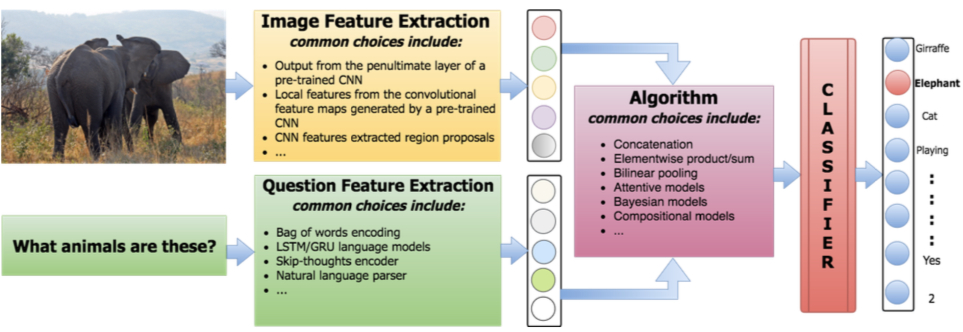
Existing algorithms generally include the following structures:
-
Extract image features
-
Extract question features
-
Algorithm that uses features to produce results
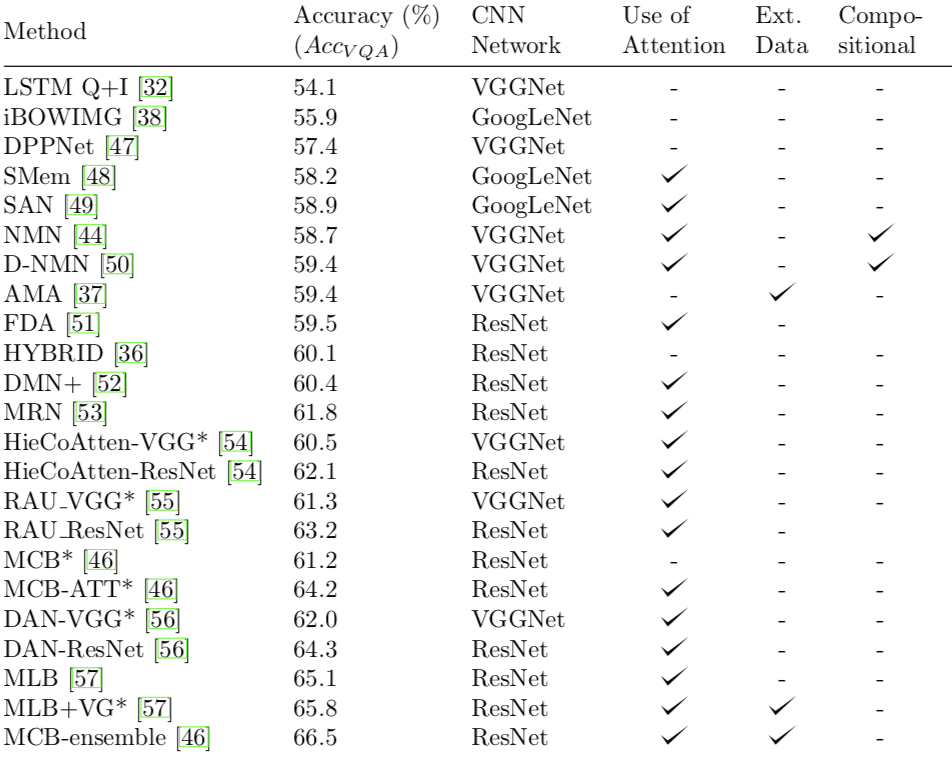
Baseline and Model Performance
-
Randomly guess the most likely answer. “yes”/“no”
-
MLP (multi-layer perceptron)
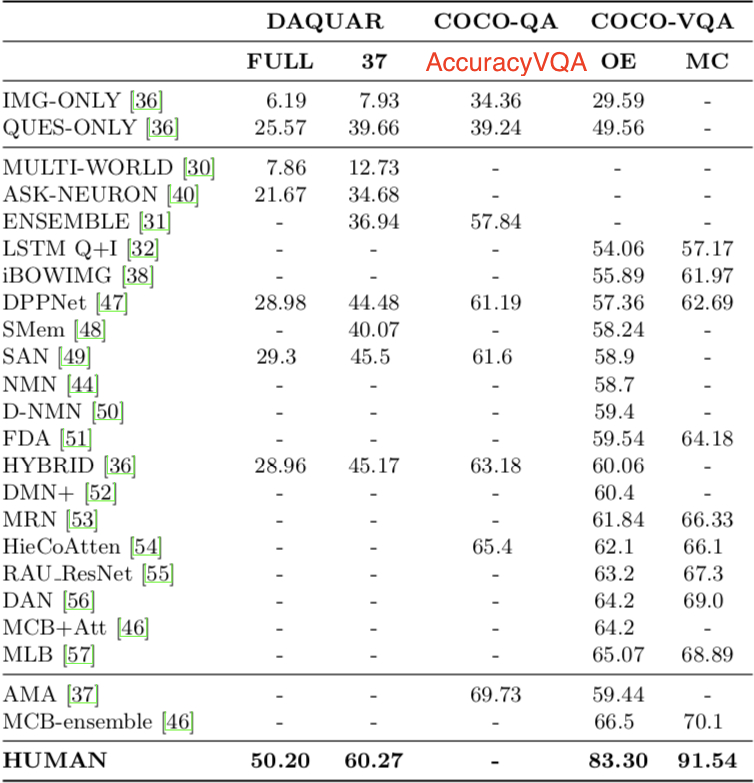
Model Architecture Overview
-
Bayesian and question-oriented models
-
Attention mechanism-based models
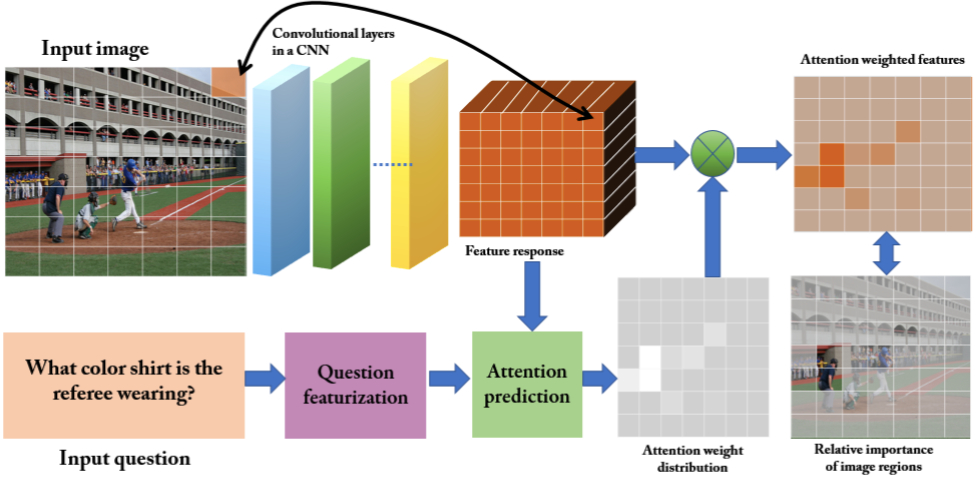
-
Nonlinear pooling methods
-
MULTI-WORLD: A multi-world approach to question answering about real-world scenes based on uncertain input, NIPS2014
-
ASK-NEURon: Ask your neurons: A neural-based approach to answering questions about images, ICCV2015
-
ENSEMBLE: Exploring models and data for image question answering, NIPS2015
-
LSTM Q+I: VQA: Visual question answering, ICCV2015
-
iBOWIMG: Simple baseline for visual question answering, arxiv
-
DPPNET: Image question answering using convolutional neural network with dynamic parameter prediction, CVPR2016
-
SMem: Ask, attend and answer: Exploring question-guided spatial attention for visual question answering, ECCV2016
-
SAN: Stacked attention networks for image question answering, CVPR2016
-
NMN: Deep compositional question answering with neural module networks, CVPR2016
-
FDA: A focused dynamic attention model for visual question answering, arxiv2016
-
HYBRID: Answer-type prediction for visual question answering, CVPR2016
-
DMN+: Dynamic memory networks for visual and textual question answering, ICML2016
-
MRN: Multimodal residual learning for visual qa, NIPS2016
-
HieCoAtten: Hierarchical question-image co-attention for visual question answering, NIPS2016
-
RAU_ResNet: Training recurrent answering units with joint loss minimization for VQA, arxiv2016
-
DAN: Dual attention networks for multimodal reasoning and matching, arxiv2016
-
MCB+Att: Multi-modal compact bilinear pooling for visual question answering and visual grounding, EMNLP2016
-
MLB: Hadamard product for low-rank bilinear pooling, arxiv2016
-
AMA: Ask me anything: Free-form visual question answering based on knowledge from external sources, CVPR2016
-
MCB-ensemble: Multi-modal compact bilinear pooling for visual question answering and visual grounding, EMNLP2016
VQA Still Has Many Problems
Although VQA has made great progress, existing algorithms still have a huge gap from humans.
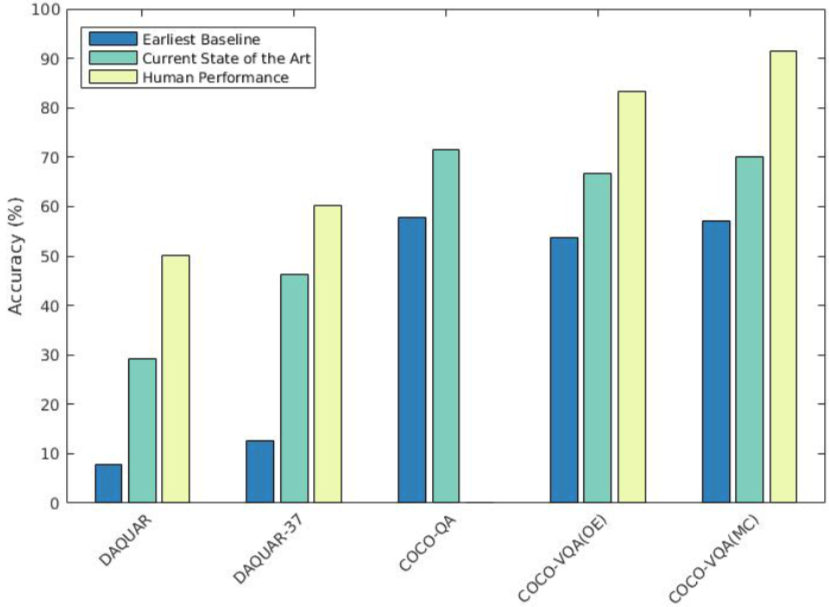
Existing problems include:
-
Existing VQA systems rely too much on questions rather than image content, and language bias seriously affects VQA system performance.
-
Answers can be guessed with just questions or images. Even a poor dataset (usually containing biased questions) will reduce VQA system performance. That is, the more specific the question, the better! [do->play->sport play]
-
Does the improvement in algorithm performance really come from attention mechanisms?
-
Good results can also be achieved through multiple global image features (pre-trained VGG-19, ResNet-101).
-
Attention mechanisms sometimes mislead VQA systems.
Conclusion
An algorithm that can answer any questions about images will be a milestone in artificial intelligence.
Research Direction Potential Stocks
-
Larger, more unbiased, and richer datasets: Each question’s weight should not be the same; question quality should be higher; answers should not be binary; multiple-choice questions should be eliminated
-
More clever model evaluation methods
-
Focus: algorithms that can reason about image content!
-
Common sense reasoning.
-
Spatial location.
-
Answer questions at different granularities.

