Paper Basic Information
-
Paper Title: Deep Reinforcement Learning for Dialogue Generation
-
Paper Link: https://arxiv.org/abs/1606.01541
-
Source Code:
-
https://github.com/liuyuemaicha/Deep-Reinforcement-Learning-for-Dialogue-Generation-in-tensorflow
-
About Authors:
-
Jiwei Li: Stanford University PhD graduate, citation count as of publication: 2156
-
Will Monroe: Stanford University PhD student, citation count as of publication: 562
-
Alan Ritter: Ohio State University Professor, citation count as of publication: 4608
-
Michel Galley: Microsoft Senior Researcher, citation count as of publication: 4529
-
Jianfeng Gao: Microsoft Research Redmond (headquarters), citation count as of publication: 11944
-
Dan Jurafsky: Stanford University Professor, citation count as of publication: 32973
-
About Note Author:
-
Zhengyuan Zhu, Beijing University of Posts and Telecommunications graduate student, research direction: multimodal and cognitive computing.
Paper Recommendation Reason and Abstract
Recent neural models for dialogue generation have greatly helped conversational agents generate responses, but the results are often shortsighted: predicting one utterance at a time ignores their impact on future outcomes. Modeling future dialogue direction is crucial for producing coherent and interesting dialogues. Such dialogues require the use of reinforcement learning on top of traditional NLP dialogue model techniques. In this paper, we will demonstrate how to integrate these goals by applying deep reinforcement learning to model future rewards in chatbot dialogues. The model simulates dialogues between two virtual agents, using policy gradient methods to reward sequences that exhibit three useful conversational properties: informativeness, coherence, and ease of answering (related to forward-looking function). We evaluate our model on diversity, length, and human judgment, showing that the proposed algorithm produces more interactive responses and manages to promote more persistent dialogues in dialogue simulation. This work marks the first step toward learning neural dialogue models based on long-term success of dialogues.
Dialogue System Flaws No Longer Fatal: Dawn Brought by Deep Reinforcement Learning
Introduction
Paper Writing Motivation
Seq2Seq Model: Transforms a sequence from one domain (such as an English sentence) into a sequence from another domain (such as a Chinese sentence). In the paper, it is a neural generative model that maximizes the probability of generating a response based on previous dialogue.
Although Seq2Seq models have achieved some success in dialogue generation systems, two problems remain:
-
SEQ2SEQ models are trained using maximum likelihood estimation (MLE) objective function, predicting the next utterance given the context. SEQ2SEQ models tend to generate highly generic responses, such as “I don’t know”, etc. However, “I don’t know” is obviously not a good response.
-
Maximum likelihood estimation-based Seq2Seq models cannot solve the repetition problem, so dialogue systems often fall into infinite loops of repetitive responses.
The above problems are illustrated in the following figure:

Paper Approach Highlights
First, propose two capabilities dialogue systems should have:
-
Better model the true goal of chatbot development by incorporating developer-defined reward functions.
-
Model the long-term impact of generated responses in ongoing dialogues.
Then propose using reinforcement learning generation methods to improve dialogue systems:
encoder-decoder architecture: A standard neural machine translation method, a recurrent neural network for solving seq2seq problems. Policy Gradient:
The model uses an encoder-decoder structure as the backbone, simulating dialogues between two agents while learning to maximize expected returns and exploring the possible activity space (possible responses). Agents learn policies by optimizing long-term reward functions from ongoing dialogues. The learning method uses policy gradients rather than maximum likelihood.
The improved model is shown in the following figure:

Paper Model Details
Symbols and Definitions
-
$p$: Sentence generated by the first Agent
-
$q$: Sentence generated by the second Agent
-
$p_1,q_1,p_2,q_2,…,p_i,q_i$: A dialogue, or context.
-
$[p_i,q_i]$: The state the Agent is in, i.e., the Agent’s previous two rounds of dialogue.
-
$p_{RL}(p_{i+1}|p_i,q_i)$: Policy, appearing in the paper as an LSTM encoder-decoder.
-
$r$: Reward function for each action (each round of dialogue).
-
$\mathbb{S}$: Artificially constructed “dull responses”, such as “I don’t know what you’re saying”.
-
$N_{\mathbb{S}}$: Represents the cardinality of $N_{\mathbb{S}}$
-
$N_{s}$: Represents the number of symbols for “dull response” $s$.
-
$p_{seq2seq}$: Represents the likelihood output of the SEQ2SEQ model
-
$h_{p_i}$ and $h_{p_{i+1}}$: Obtained from the encoder, representing the Agent’s two consecutive dialogues $p_i$ and $p_{i+1}$.
Definition and Role of Reward:
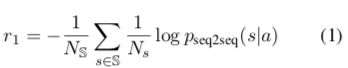
$N_{\mathbb{S}}$: Represents the cardinality of $N_{\mathbb{S}}$ $N_{s}$: Represents the number of symbols for “dull response” $s$ $p_{seq2seq}$: Represents the likelihood output of the SEQ2SEQ model
- $r_1$ is to reduce response difficulty. This reward function is inspired by the forward-looking function: calculating the probability that the model outputs $s$ when the model-generated response $a$ is used as input, summing over all sentences in the $\mathbb{S}$ set. Because $p_{seq2seq}$ is definitely less than 1, the log term is greater than zero, so r1 is less than zero. Through r1’s reward mechanism, the actions the model ultimately produces will gradually move away from dull responses, and will also to some extent estimate the next person’s reply, making it easier for the other party to respond.
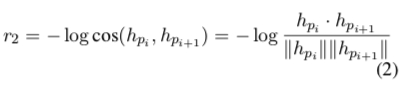
$h_{p_i}$ and $h_{p_{i+1}}$: Obtained from the encoder, representing the Agent’s two consecutive dialogues $p_i$ and $p_{i+1}$.
- $r_2$ is to increase the richness of information flow, avoiding high similarity between two responses. So r2 uses cosine similarity to calculate the semantic similarity between two sentences. It’s easy to see that r2 is also a number less than zero, used to penalize similar sentences.
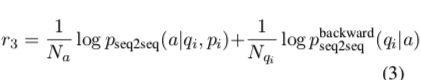
$p_{seq2seq}(a|p_i, q_i)$: Represents the probability of generating response a given the dialogue context $[p_i,q_i]$ $p^{backward}_{seq2seq}(q_i|a)$: Represents the probability of generating the previous dialogue $q_i$ based on response $a$.
- $r_3$ is to enhance semantic coherence, avoiding the model only producing high-reward responses while losing sufficiency and coherence in answers. To solve this problem, the model uses mutual information. The backward seq2seq is another model trained with source and target reversed. The purpose of doing this is to improve the mutual relationship between q and a, making the dialogue more sustainable. It can be seen that both terms of $r_3$ are positive values.
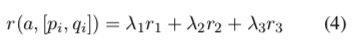
- The final reward function is a weighted sum of $r_1, r_2, r_3$. In the paper, $\lambda_1=0.25, \lambda_2=0.25, \lambda_3=0.5$ are set. Finally, when training the overall model, a basic model is first pre-trained using the Seq2Seq model, and then on its basis, policy gradient training is used with reward to optimize the model’s effectiveness.
Reinforcement Learning Model Details
Fully supervised setting: A pre-trained SEQ2SEQ model used to initialize the reinforcement learning model. Attention Model: When the model produces output, it also produces an “attention range” indicating which parts of the input sequence to focus on when producing the next output, then generates the next output based on the focused region, and so on.
The paper adopts an AlphaGo-style model: initializing the reinforcement learning model through a general response generation policy in a fully supervised environment. Among them, the SEQ2SEQ model incorporates an Attention mechanism and this model was trained on the OpenSubtitles dataset.
The paper does not use a pre-trained Seq2Seq model to initialize the reinforcement learning policy model, but instead uses an encoder-decoder model proposed by the first author in 2016 that generates maximum mutual information responses: using $p_{SEQ2SEQ}(a|p_i, q_i)$ to initialize $p_{RL}$. Obtaining the mutual information score $m(\hat{a}, [p_i, q_i])$ from the generated candidate set $A={\hat{a}|\hat{a}~p_{RL}}$ for $\hat{a}$, then the expected reward function for a sequence is:
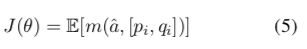
The gradient through likelihood rate estimation is:
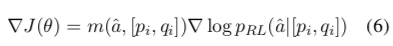
The encoder-decoder parameters can be updated through stochastic gradient descent. The paper improved the gradient by borrowing from the curriculum learning strategy.
The final gradient is:
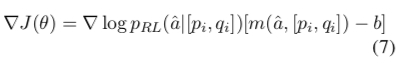
During model optimization, policy gradient is used to find parameters that can maximize the reward function:
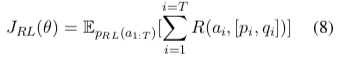
Simulation Experiment Details
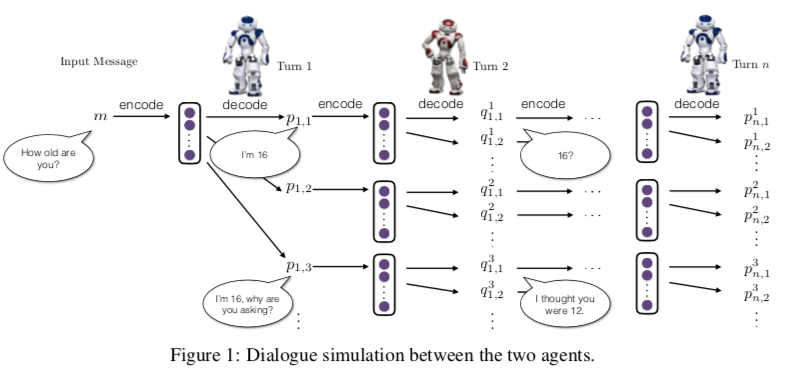
Dialogue Simulation Process:
-
Select a message from the training set and give it to Agent-A
-
Agent-A encodes the message and decodes an output response.
-
Agent-B takes Agent-A’s output as input and through encoder-decoder
The policy is the probability distribution of responses generated by the Seq2Seq model. We can view this problem as inputting dialogue history context into a neural network, then the output is a probability distribution of responses: $pRL(pi+1|pi,qi)$. The so-called policy is random sampling, selecting which response to make. Finally, policy gradient is used to train the network parameters.
Two agents converse with each other, and the final reward is used to adjust the base model’s parameters.
Experimental Results Analysis
Evaluation Metrics
BLEU: bilingual evaluation understudy, an algorithm for evaluating machine translation accuracy. The paper does not use the widely applied BLEU as an evaluation criterion.
- Dialogue length. The author believes that when dull responses appear in dialogue, it counts as the end of dialogue, so the number of dialogue rounds is used as an evaluation metric:

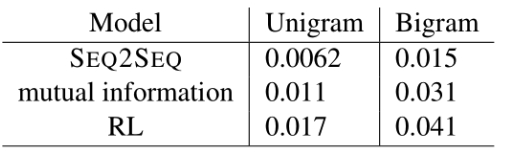
- Number and diversity of different unigrams, bigrams tuples, used to evaluate the richness of answers the model produces:
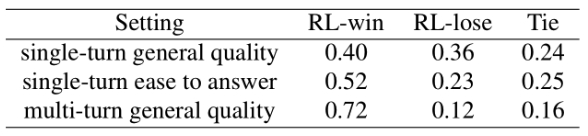
- Human scoring:
- Final dialogue effectiveness
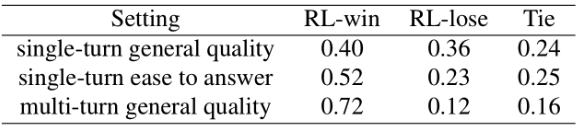
Conclusion
The author uses deep reinforcement learning methods to improve multi-turn dialogue effectiveness and proposes three ways of defining rewards. It can be considered a fairly good example of combining DRL with NLP. However, it can also be seen from the final results section that the author did not use the widely used BLEU metric for either reward definition or final evaluation metrics. This manually defined reward function cannot possibly cover all aspects of an ideal dialogue’s characteristics.

