Basic Paper Information
Paper Name: Video Captioning via Hierarchical Reinforcement Learning
Paper Link: https://ieeexplore.ieee.org/document/8578541/
Paper Source Code:
-
None
About Note Author:
- Zhu Zhengyuan, graduate student at Beijing University of Posts and Telecommunications, research direction is multimodal and cognitive computing.
Paper Recommendation Reason
Fine-grained action description in video captioning is still a huge challenge in this field. The paper’s innovations are divided into two parts: 1. Through hierarchical reinforcement learning framework, using high-level manager to identify coarse-grained video information and control description generation goals, using low-level worker to identify fine-grained actions and complete goals. 2. Propose the Charades dataset.
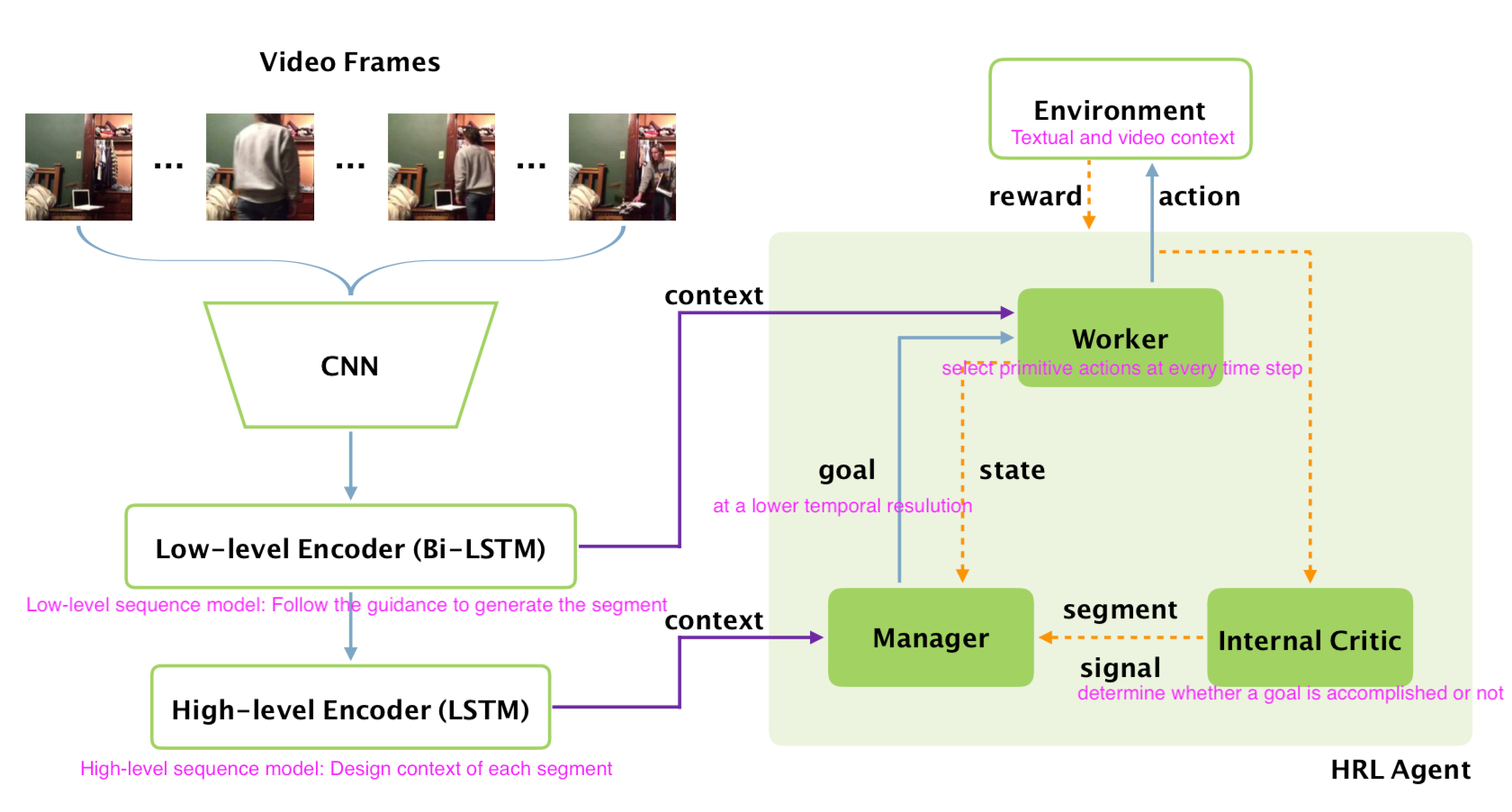
Video Captioning via Hierarchical Reinforcement Learning

Framework of Model
Work processing
Pretrained CNN encoding stage we obtain: video frame features: $v={v_i}$, where $i$ is index of frames.
Language Model encoding stage we obtain: Worker : $h^{E_w}={h_i^{E_w}}$ from low-level Bi-LSTM encoder Manager: $h^{E_m}={h_i^{E_m}}$ from high LSTM encoder
HRL agent decoding stage we obtain: Language description:$a*{1}a*{2}…a_{T}$, where $T$ is the length of generated caption.
Details in HRL agent:
-
High-level manager:
-
Operate at lower temporal resolution.
-
Emits a goal for worker to accomplish.
-
Low-level worker
-
Generate a word for each time step by following the goal.
-
Internal critic
-
Determine if the worker has accomplished the goal
Details in Policy Network:
-
Attention Module:
-
At each time step t: $ct^W=\sum\alpha{t,i}^{W}h^{E_w}_i$
-
Note that attention score $\alpha*{t,i}^{W}=\frac{exp(e*{t, i})}{\sum_{k=1}^{n}exp(et, k)}$, where $e{t,i}=w^{T} tanh(W*{a} h*{i}^{Ew} + U{a} h^{W}_{t-1})$
-
Manager and Worker:
-
Manager: take $[c_t^M, h_t^M]$ as input to produce goal. Goal is obtained through an MLP.
-
Worker: receive the goal $g_t$ and take the concatenation of $c_t^W, gt, a{t-1}$ as input, and outputs the probabilities of $\pi_t$ over all action $a_t$.
-
Internal Critic:
-
evaluate worker’s progress. Using an RNN structure takes a word sequence as input to discriminate whether end.
-
Internal Critic RNN take $h^I_{t-1}, a_t$ as input, and generate probability $p(z_t)$.
Details in Learning:
-
Definition of Reward: $R(at)$ = $\sum{k=0} \gamma^{k} f(a_{t+k})$ , where $f(x)=CIDEr(sent+x)-CIDEr(sent)$ and $sent$ is previous generated caption.
-
Pseudo Code of HRL training algorithm:
`import training_pairs
import pretrained_CNN, internal_critic
for i in range(M):
Initial_random(minibatch)
if Train_Worker:
goal_exploration(enable=False)
sampled_capt = LSTM() # a_1, a_2, ..., a_T
Reward = [r_i for r_i in calculate_R(sampled_caption)]
Manager(enable=False)
worker_policy = Policy_gradient(Reward)
elif Train_Manager:
Initial_random_process(N)
greedy_decoded_cap = LSTM()
Reward = [r_i for r_i in calculate_R(sampled_caption)]
Worker(enable=False)
manager_policy = Policy_gradient(Reward)
`All in one
Dataset
This dataset contains 50 hours of video and 260,000 related video descriptions.
Charades Captions: 9,848 videos of indoor interactions, including 66,500 annotations of 157 actions, 41,104 labels of objects from 46 categories, and a total of 27,847 text descriptions.
Experimental Results
Experiment visualization

Model comparison